The article has been translated automatically. Any images and tables cited in the articles can be found by downloading the magazine issue in PDF format. Show original:
The article has been translated automatically. Any images and tables cited in the articles can be found by downloading the magazine issue in PDF format. Show original:
Introduzione: la disponibilità di strumenti di comunicazione universali e il loro impatto sull’assistenza sanitaria
Permettere a tutti di capire ed essere capiti nella propria lingua è una delle sfide più significative per l’umanità. Il raggiungimento di questo obiettivo faciliterà una collaborazione senza precedenti tra gli esseri umani. Immagina, ad esempio, se la ricerca scientifica fosse disponibile nella lingua di ogni ricercatore non appena è stata pubblicata. Non siamo lontani da ciò, come dimostrato dalla ricerca che conduciamo a Translated, un fornitore globale di servizi linguistici e pioniere dei servizi di traduzione basati sull’intelligenza artificiale. Questa ricerca innovativa è stata presentata all’ultima conferenza annuale dell’Associazione per la traduzione automatica nelle Americhe (AMTA) a Orlando.
Analizzando le modifiche apportate da 136.000 dei migliori traduttori professionisti al mondo a 2 miliardi di frasi elaborate da software di traduzione automatica (traduzione automatica), per la prima volta nella storia, siamo stati in grado di quantificare la velocità con cui ci stiamo avvicinando alla singolarità nella traduzione. La singolarità si raggiunge quando i migliori traduttori professionisti passano lo stesso tempo a correggere una traduzione prodotta dalla traduzione automatica (MT) come fanno a correggere quella completata dai loro colleghi.
In campo medico, rompere le barriere linguistiche è ancora più importante che in altri settori. Queste barriere impediscono ai pazienti di comprendere chiaramente le loro condizioni cliniche, rendendo così difficile per loro aderire correttamente alla terapia necessaria. Inoltre, queste barriere rendono difficile, se non impossibile, per i medici di acquisire il consenso richiesto per la cura e limitare i dati e le informazioni necessarie per la diagnosi e la ricerca. Oggi, molte grandi istituzioni sanitarie offrono servizi di interpretariato, ma questi hanno costi significativi. Pertanto, la maggior parte delle organizzazioni nel settore medico si affida ancora a mediatori culturali o soluzioni fai-da-te, come le app per smartphone. La pandemia di Covid19 ha reso più importante che mai la necessità di affrontare questo problema. Secondo la Commissioneeuropea1, la pandemia ha aumentato la domanda di traduzione del 49% nel settore sanitario. Fortunatamente, i progressi tecnologici stanno spingendo la comunità sanitaria a considerare la traduzione automatica come un mezzo per superare le barriere linguistiche e gli strumenti di comunicazione universali sono abbastanza vicini da fornire un supporto equivalente.
Ci aspettiamo che la traduzione automatica avrà un impatto positivo radicale sul settore sanitario. Le potenziali applicazioni sono in tre aree principali:
– La traduzione di informazioni per il generale
– La traduzione di pubblicazioni specializzate come articoli scientifici, brevetti e relazioni sulle malattie. Ciò fornirà l’accesso a studi di ricerca globali e dati del mondo reale (ad esempio studi clinici e scoperta di farmaci).
– Comunicazione senza soluzione di continuità con il paziente medico e raccolta di feedback dei pazienti, anche dalle discussioni che si svolgono sui social media tra Here, possiamo combinare MT con riconoscimento vocale automatico (ASR) e tecnologie di sintesi vocale (TTS) per supportare la lingua parlata.
Tuttavia, la traduzione automatica funzionerà bene nel settore sanitario solo quando fornisce traduzioni altrettanto buone di quelle fatte dai professionisti della traduzione. In Translated, monitoriamo la qualità della traduzione automatica dal 2011 e, di recente, abbiamo deciso di utilizzare l’enorme quantità di dati che abbiamo raccolto per misurare quanto siamo lontani dal fornire una traduzione automatica di qualità umana. Quando raggiungiamo la singolarità nella traduzione, possiamo integrare la traduzione automatica in tempo reale in quasi tutti i servizi a un costo molto accessibile.
Breve storia della traduzione automatica
Il concetto di traduzione automatica è stato menzionato per la prima volta nelIX secolo quando un crittografo arabo introdusse tecniche per la traduzione sistematica della lingua che sono, incredibilmente, ancorarilevanti. Tuttavia, la prima dimostrazione pubblica di traduzione automatica è stata fatta nel 1954 negli Stati3Uniti. È stato un piccolo esperimento, ma ha incoraggiato i ricercatori ad andare avanti. I primi sistemi si basavano su dizionari bilingue e regole che stabilivano come tradurre parole o frasi da una lingua di origine in una lingua di destinazione. Successivamente, è stato sviluppato un approccio statistico: analizzando grandi volumi di traduzioni umane, le macchine hanno iniziato a prevedere l’equivalenza di una frase nella lingua di destinazione. L’approccio incentrato sull’apprendimento dei modelli e sulla previsione dei modelli ha guidato la prima versione di Google Translate nei primi anni 2000.
Oggi, Google Translate e i più avanzati motori di traduzione automatica si affidano a modelli di rete neurale basati sul deep learning per apprendere e prevedere gli output finali. Questa è una forma più profonda e affidabile di rilevamento e previsione dei modelli. In questo tipo di sistema, la traduzione è prodotta da un singolo modello di sequenza addestrato a prevedere una parola alla volta, considerando l’intera frase di origine e la traduzione che è già stata fornita.
Nel 2017, un consorzio composto da Translated, la Fondazione Bruno Kessler, l’Università di Edimburgo e TAUS ha introdotto la prima traduzione automatica adattiva,ModernMT4. Inizialmente era un progetto di ricerca sostenuto dall’Unione europea che5 in seguito divenne software open source e un servizio commerciale alimentato da Translated. In questo nuovo modello, MT impara in tempo reale dal feedback correttivo del traduttore senza riqualificare il modello di traduzione. L’idea della traduzione automatica adattiva risale a un precedente progetto di ricerca condotto da Translated, dalla Fondazione Bruno Kessler, dall’Università di Edimburgo e dall’Università di Le Mans, sponsorizzato nuovamente dall’Unione6europea. L’idea iniziale era quella di creare uno strumento per modificare i risultati della traduzione automatica e gestire i flussi di lavoro di localizzazione. L’obiettivo della ricerca era un sistema di traduzione automatica che potesse imparare dalle correzioni dei traduttori e migliorare automaticamente nel tempo. La componente MT della soluzione è stata successivamente separata per concentrarsi sullo strumento di editing, che è stato finalmente rilasciato come software open source nel 2014. La Commissione europea ha incluso il progetto tra quelli con il più alto potenziale di innovazione finanziato dal Settimo programma quadro. Translated ha perfezionato ulteriormente il prototipo di ricerca e ha creato una versione commerciale,Matecat7, uno strumento di traduzione assistita da computer gratuito e un software di editing MT che l’azienda ha adottato come strumento di produzione esclusivo. Con Matecat e ModernMT, Translated sta spingendo forte per una perfetta simbiosi tra creatività umana e intelligenza artificiale: rimuovendo compiti ridondanti, l’IA consente ai professionisti di concentrarsi sulle sfumature del linguaggio, migliorando la qualità della traduzione. Questa sinergia offre ai linguisti suggerimenti migliori mentre la MT continua ad apprendere. Insieme, diventano ogni giorno più efficienti, capaci di adattarsi ed efficaci in termini di costi.
Informazioni sul processo e sui dati raccolti
Nel 2011, Translated ha standardizzato e stabilito una metrica altamente affidabile per valutare accuratamente la qualità della MT. Lo chiamiamo Time to Edit (TTE): questo è il tempo medio per parola richiesto dai traduttori professionisti più performanti per controllare e correggere le traduzioni suggerite da MT. Ciò consente di passare da stime automatizzate ancora in uso nel settore a misurazioni dello sforzo cognitivo umano, riassegnando la valutazione della qualità a persone tradizionalmente responsabili del compito: traduttori professionisti. Abbiamo monitorato Time to Edit per quasi un decennio, raccogliendo oltre 2 miliardi di modifiche su frasi tradotte in modo efficace da 136.000 traduttori professionisti in tutto il mondo che lavorano su più settori tematici, che vanno dalla letteratura alla traduzione tecnica e includono campi in cui la traduzione automatica è ancora in difficoltà, come la trascrizione vocale. I linguisti sono stati selezionati per i lavori specifici che hanno completato utilizzando l’intelligenza artificiale proprietaria8chiamata TRank, che raccoglie dati sulle prestazioni lavorative e sulle qualifiche su oltre 300.000 liberi professionisti che hanno lavorato con l’azienda negli ultimi due decenni. L’intelligenza artificiale considera oltre 30 fattori, tra cui la corrispondenza del curriculum, le prestazioni di qualità, il record di consegna puntuale, la disponibilità e l’esperienza in aree tematiche specifiche del dominio.
Lavorando in Matecat, i traduttori controllano e correggono i suggerimenti di traduzione forniti dal motore MT di loro scelta. I dati sono stati inizialmente raccolti utilizzando la MT statistica di Google (2015-2016), quindi la MT neurale di Google e, più recentemente, la MT neurale adattiva di Modern MT, introdotta nel 2018, che è diventata rapidamente la scelta preferita tra quasi tutti i nostri traduttori. Translated ha raccolto il tempo medio per modificare una parola in modo continuo per oltre sette anni.
Per affinare il campione, abbiamo considerato solo quanto segue:
– Lavori completati consegnati ad un alto livello di qualità.
– Frasi con suggerimenti MT che non avevano corrispondenza da database di segmenti di testo precedentemente tradotti.
– Lavori in cui la lingua di destinazione ha una grande quantità di dati disponibili insieme a comprovata efficienza MT (inglese, francese, tedesco, spagnolo, italiano e portoghese).
Dal pool di frasi risultante, abbiamo rimosso:
– Frasi che non hanno ricevuto alcuna modifica poiché non hanno fornito informazioni su TTE e frasi che hanno richiesto più di 10 secondi per parola per essere modificate, poiché suggeriscono interruzioni e/o complessità insolitamente elevate. Questo perfezionamento è stato necessario per rendere possibile il confronto TTE tra più
– Lavori di adattamento al locale, cioè traduzioni tra varianti di una sola lingua (ad esempio inglese britannico a inglese americano), dal momento che questi non sono rappresentativi del problema a
– Grandi lavori dei clienti, dal momento che impiegano modelli linguistici altamente personalizzati e memorie di traduzione in cui le prestazioni TTE sono di gran lunga migliori della media.
Time to Edit è influenzato da due variabili principali diverse dalla qualità MT: l’evoluzione dello strumento di editing e la qualità fornita dal traduttore. L’influenza di questi due fattori può essere considerata trascurabile se si considera la tendenza di miglioramento a lungo termine che abbiamo osservato.
Una sorprendente tendenza lineare che si avvicina alla singolarità nella traduzione
Se tracciati graficamente, i dati TTE mostrano una tendenza sorprendentemente lineare. La nostra ipotesi iniziale per spiegare questo è che ogni unità di progresso per colmare il divario di qualità richiede esponenzialmente più risorse rispetto all’unità precedente, e di conseguenza distribuiamo quelle risorse: potenza di calcolo (raddoppiando ogni due anni), disponibilità dei dati (il numero di parole tradotte in pieghe a un tasso di crescita annuo composto del 6,2% secondo Nimdzi Insights) e l’efficienza degli algoritmi di apprendimento automatico (calcolo necessario per la formazione, miglioramento 44x dal 2012-2019, secondo OpenAI|||UNTRANSLATED_CONTENT_START|||9).|||UNTRANSLATED_CONTENT_END|||
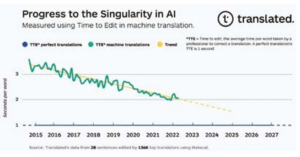
Fig. 1.
Conclusione: quanto siamo vicini a rompere le barriere linguistiche
Se i progressi nella qualità della traduzione automatica continuano con la tendenza attuale, in circa sei anni i traduttori professionisti più performanti passeranno lo stesso tempo a correggere una traduzione prodotta dalla traduzione automatica come fanno a correggere quella completata dai loro colleghi. La data esatta in cui raggiungeremo la singolarità nella traduzione potrebbe variare un po ‘, ma la tendenza è chiara. Siamo quindi vicini a essere in grado di fornire in tempo reale, strumenti di traduzione universali e accessibili che romperanno le barriere linguistiche, permettendoci di migliorare i risultati di salute dei clienti, riducendo il rischio di morte.
Da un punto di vista della ricerca, le prove che Translated ha fornito sui progressi nella qualità della MT sono molto probabilmente la prova più convincente del successo su larga scala visto nelle comunità MT e AI in generale. In effetti, molti ricercatori di intelligenza artificiale pensano che risolvere il problema della traduzione linguistica equivalga a produrre intelligenza generale artificiale (AGI). La scoperta di Translated ha così quantificato, per la prima volta nella storia, la velocità con cui ci stiamo avvicinando alla singolarità nell’intelligenza artificiale l’ipotetico punto futuro nel tempo in cui l’intelligenza artificiale trascende l’intelligenza umana.