The article has been translated automatically. Any images and tables cited in the articles can be found by downloading the magazine issue in PDF format. Show original:
The article has been translated automatically. Any images and tables cited in the articles can be found by downloading the magazine issue in PDF format. Show original:
Introduction : La disponibilité des outils de communication universels et leur impact sur les soins de santé
Permettre à chacun de comprendre et d’être compris dans sa propre langue est l’un des défis les plus importants pour l’humanité. Cela facilitera une collaboration sans précédent entre les êtres humains. Imaginez, par exemple, si la recherche scientifique était disponible dans la langue de chaque chercheur dès sa publication. Nous ne sommes pas loin de cela, comme le prouvent les recherches que nous menons chez Translated, un fournisseur mondial de services linguistiques et pionnier des services de traduction alimentés par l’IA. Cette recherche révolutionnaire a été présentée lors de la dernière conférence annuelle de l’Association for Machine Translation in the Americas (AMTA) à Orlando.
En analysant les modifications apportées par 136 000 des meilleurs traducteurs professionnels au monde à 2 milliards de phrases traitées par un logiciel de traduction automatique (traduction automatique), pour la première fois dans l’histoire, nous avons pu quantifier la vitesse à laquelle nous approchons de la singularité de la traduction. La singularité est atteinte lorsque les traducteurs professionnels les plus performants passent le même temps à corriger une traduction produite par traduction automatique (MT) qu’à corriger une traduction complétée par leurs pairs.
Dans le domaine médical, briser les barrières linguistiques a encore plus d’impact que dans d’autres domaines. Ces obstacles empêchent les patients de comprendre clairement leurs conditions cliniques, ce qui les empêche d’adhérer correctement au traitement nécessaire. En outre, ces obstacles font qu’il est difficile, voire impossible, pour les médecins d’obtenir le consentement requis pour les soins et limitent les données et les informations nécessaires aux diagnostics et à la recherche. Aujourd’hui, de nombreux grands établissements de santé offrent des services d’interprétation, mais ceux-ci coûtent cher. Ainsi, la plupart des organisations du secteur médical comptent toujours sur des médiateurs culturels ou des solutions de bricolage, telles que les applications pour smartphones. La pandémie de Covid19 a rendu la nécessité de s’attaquer à ce problème plus importante que jamais. Selon la Commissioneuropéenne1, la pandémie a augmenté la demande de traduction de 49 % dans le secteur de la santé. Heureusement, les progrès technologiques poussent la communauté des soins de santé à considérer la traduction automatique comme un moyen de surmonter les barrières linguistiques, et les outils de communication universels sont suffisamment proches pour fournir un soutien équivalent.
Nous nous attendons à ce que la traduction automatique ait un impact radicalement positif sur le secteur de la santé. Les applications potentielles sont dans trois domaines principaux :
– La traduction des informations pour le compte du
– La traduction de publications spécialisées telles que des articles scientifiques, des brevets et des rapports de maladie. Cela donnera accès à des études de recherche mondiales et à des données du monde réel (par exemple, des essais cliniques et la découverte de médicaments).
– Communication transparente entre le médecin et le patient et collecte des commentaires des patients, même lors de discussions sur les médias sociaux parmi Here, nous pouvons combiner la MT avec les technologies de reconnaissance automatique de la parole (ASR) et de synthèse vocale (TTS) pour prendre en charge le langage parlé.
Cependant, la traduction automatique ne fonctionnera bien dans les soins de santé que lorsqu’elle fournira des traductions aussi bonnes que celles effectuées par des professionnels de la traduction. Chez Translated, nous surveillons la qualité de la traduction automatique depuis 2011, et récemment, nous avons décidé d’utiliser la quantité massive de données que nous avons collectées pour mesurer à quel point nous sommes loin de fournir une traduction automatique de qualité humaine. Lorsque nous atteignons la singularité dans la traduction, nous pouvons intégrer la traduction automatique en temps réel dans presque tous les domaines à un coût très accessible.
Une brève histoire de la traduction automatique
Le concept de traduction automatique a été mentionné pour la première fois au IXesiècle lorsqu’un cryptographe arabe a introduit des techniques de traduction linguistique systématique qui sont, incroyablement, toujours d’actualité2. Cependant, la première démonstration publique de traduction automatique a été faite en 1954 aux3États-Unis. C’était une petite expérience, mais elle a encouragé les chercheurs à aller de l’avant. Les premiers systèmes reposaient sur des dictionnaires bilingues et des règles indiquant comment traduire des mots ou des phrases d’une langue source dans une langue cible. Ensuite, une approche statistique a été développée : en analysant de grands volumes de traductions humaines, les machines ont commencé à prédire l’équivalence d’une phrase dans la langue cible. L’approche axée sur l’apprentissage des modèles et la prévision des modèles a conduit à la première version de Google Translate au début des années 2000.
Aujourd’hui, Google Translate et les moteurs de traduction automatique les plus avancés s’appuient sur des modèles de réseaux neuronaux basés sur l’apprentissage profond pour apprendre et prédire les résultats finaux. Il s’agit d’une forme plus profonde et plus fiable de détection et de prévision des modèles. Dans ce type de système, la traduction est produite par un modèle de séquence unique formé pour prédire un mot à la fois, en tenant compte de la phrase source entière et de la traduction qui a déjà été fournie.
En 2017, un consortium composé de Translated, de la Fondazione Bruno Kessler, de l’Université d’Édimbourg et de TAUS a lancé la première traduction automatique adaptative,ModernMT4. Il s’agissait initialement d’un projet de recherche soutenu par l’Union européennee
5 qui est devenu plus tard un logiciel open source et un service commercial alimenté par Translated. Dans ce nouveau modèle, MT apprend en temps réel de la rétroaction corrective du traducteur sans recycler le modèle de traduction. L’idée de la traduction automatique adaptative remonte à un précédent projet de recherche mené par Translated, la Fondazione Bruno Kessler, l’Université d’Édimbourg et l’Université du Mans, parrainé à nouveau par l’Unioneuropéenne6. L’idée initiale était de créer un outil pour éditer les résultats de la traduction automatique et gérer les flux de travail de localisation. L’objectif de la recherche était un système de TA qui pourrait apprendre des corrections des traducteurs et s’améliorer automatiquement au fil du temps. Le composant MT de la solution a ensuite été séparé pour se concentrer sur l’outil d’édition, qui a finalement été publié en tant que logiciel open source en 2014. La Commission européenne a inclus le projet parmi ceux qui présentent le plus fort potentiel d’innovation financé par le septième programme-cadre. Translated a affiné le prototype de recherche et créé une version commerciale, Matecat7, un outil gratuit de traduction assistée par ordinateur et un logiciel d’édition MT que la société a adopté comme outil de production exclusif. Avec Matecat et ModernMT, Translated fait pression pour une symbiose parfaite entre créativité humaine et intelligence artificielle : en supprimant les tâches redondantes, l’IA permet aux professionnels de se concentrer sur les nuances du langage, améliorant ainsi la qualité de la traduction. Cette synergie donne aux linguistes de meilleures suggestions tandis que la MT continue d’apprendre. Ensemble, ils deviennent plus efficaces, adaptables et rentables chaque jour.
À propos du processus et des données collectées
En 2011, Translated a normalisé et établi une métrique très fiable pour évaluer la qualité de la MT avec précision. Nous l’appelons Time to Edit (TTE) : il s’agit du temps moyen par mot requis par les traducteurs professionnels les plus performants pour vérifier et corriger les traductions suggérées par MT. Cela permet de passer d’estimations automatisées encore utilisées dans l’industrie à des mesures de l’effort cognitif humain, en réattribuant l’évaluation de la qualité à des personnes traditionnellement responsables de la tâche : des traducteurs professionnels. Nous suivons Time to Edit depuis près d’une décennie, collectant plus de 2 milliards de modifications sur des phrases traduites efficacement par 136 000 traducteurs professionnels dans le monde entier, travaillant dans de multiples domaines, allant de la littérature à la traduction technique, en passant par les domaines dans lesquels MT est encore en difficulté, tels que la transcription de la parole. Les linguistes ont été sélectionnés pour les emplois spécifiques qu’ils ont accomplis en utilisant l’IA propriétaire appelée TRank8, qui recueille des données sur les performances et les qualifications de plus de 300 000 pigistes qui ont travaillé avec l’entreprise au cours des deux dernières décennies. L’IA prend en compte plus de 30 facteurs, y compris la correspondance des CV, les performances de qualité, le respect des délais de livraison, la disponibilité et l’expertise dans des domaines spécifiques.
Travaillant chez Matecat, les traducteurs vérifient et corrigent les suggestions de traduction fournies par le moteur MT de leur choix. Les données ont d’abord été collectées à l’aide de la MT statistique de Google (2015-2016), puis de la MT neuronale de Google, et plus récemment de la MT neuronale adaptative de Modern MT, introduite en 2018, qui est rapidement devenue le choix préféré de presque tous nos traducteurs. Translated recueille le temps moyen nécessaire pour éditer un mot en continu depuis plus de sept ans.
Pour affiner l’échantillon, nous n’avons pris en compte que les éléments suivants :
– Emplois terminés livrés à un niveau élevé de qualité.
– Phrases avec des suggestions MT qui ne correspondaient pas à partir de bases de données de segments de texte précédemment traduits.
– Emplois dans lesquels la langue cible dispose d’une grande quantité de données ainsi que d’une efficacité éprouvée de la MT (anglais, français, allemand, espagnol, italien et portugais).
Dans le pool de phrases qui en résulte, nous avons supprimé :
Les phrases qui n’ont pas reçu de modifications car elles n’ont pas fourni d’informations sur TTE, et les phrases qui ont pris plus de 10 secondes par mot à éditer, car elles suggèrent des interruptions et/ou une complexité inhabituellement élevée. Ce raffinement était nécessaire pour rendre possible la comparaison TTE entre plusieurs
– Travailler sur l’adaptation à la situation locale, c’est-à-dire les traductions entre les variantes d’une seule langue (par exemple, anglais britannique vers anglais américain), car elles ne sont pas représentatives du problème à
– De gros clients, car ils utilisent des modèles linguistiques hautement personnalisés et des mémoires de traduction dans lesquelles les performances TTE sont bien meilleures que la moyenne.
Time to Edit est impacté par deux variables principales autres que la qualité MT : l’évolution de l’outil d’édition et la qualité délivrée par le traducteur. L’influence de ces deux facteurs peut être considérée comme négligeable si l’on considère la tendance à l’amélioration à long terme que nous avons observée.
Une tendance linéaire surprenante approchant la singularité en traduction
Lorsqu’elles sont tracées graphiquement, les données TTE montrent une tendance étonnamment linéaire. Notre hypothèse initiale pour expliquer cela est que chaque unité de progrès vers les services qui comblent l’écart de qualité nécessite exponentiellement plus de ressources que l’unité précédente, et nous déployons en conséquence ces ressources : puissance de calcul (doublant tous les deux ans), disponibilité des données (le nombre de mots traduits en croissances à un taux de croissance annuel composé de 6,2% selon Nimdzi Insights), et l’efficacité des algorithmes d’apprentissage automatique (calcul nécessaire à la formation, amélioration de 44 fois par rapport à 2012-2019, selon OpenAI9
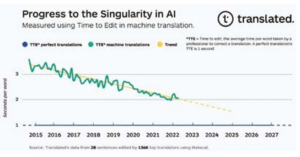
Fig. 1.
Conclusion : à quel point nous sommes proches de briser les barrières linguistiques
Si les progrès dans la qualité de la traduction automatique se poursuivent avec la tendance actuelle, dans environ six ans, les traducteurs professionnels les plus performants passeront autant de temps à corriger une traduction produite par la traduction automatique qu’à corriger une traduction effectuée par leurs pairs. La date exacte à laquelle nous atteindrons la singularité en traduction pourrait varier quelque peu, mais la tendance est claire. Nous sommes donc sur le point de pouvoir fournir des outils de traduction en temps réel, universels et accessibles qui briseront les barrières linguistiques, nous permettant d’améliorer les résultats de santé des clients et de réduire le risque de décès.
Du point de vue de la recherche, les preuves fournies par Translated sur les progrès de la qualité de la MT sont probablement les preuves les plus convaincantes de succès à grande échelle observées dans les communautés de la MT et de l’IA en général. En effet, de nombreux chercheurs en IA pensent que résoudre le problème de la traduction du langage équivaut à produire une intelligence artificielle générale (agi). La découverte de Translated a ainsi quantifié, pour la première fois dans l’histoire, la vitesse à laquelle nous approchons de la singularité de l’intelligence artificielle, le futur hypothétique auquel l’intelligence artificielle transcende l’intelligence humaine.