The article has been translated automatically. Show original:
The article has been translated automatically. Show original:
Wprowadzenie: Dostępność uniwersalnych narzędzi komunikacji i ich wpływ na opiekę zdrowotną
Umożliwienie wszystkim zrozumienia i bycia zrozumianym w ich własnym języku jest jednym z najważniejszych wyzwań dla ludzkości. Osiągnięcie tego ułatwi bezprecedensową współpracę między ludźmi. Wyobraźmy sobie na przykład, że badania naukowe są dostępne w języku każdego badacza zaraz po ich opublikowaniu. Nie jesteśmy od tego daleko, o czym świadczą badania, które prowadzimy w Translated, globalnym dostawcy usług językowych i pionierze usług tłumaczeniowych opartych na sztucznej inteligencji. To przełomowe badanie zostało zaprezentowane na ostatniej dorocznej konferencji Association for Machine Translation in the Americas (AMTA) w Orlando.
Analizując edycje dokonane przez 136 000 najlepszych profesjonalnych tłumaczy na świecie do 2 miliardów zdań przetworzonych przez oprogramowanie do automatycznego tłumaczenia (tłumaczenie maszynowe), po raz pierwszy w historii byliśmy w stanie określić ilościowo szybkość, z jaką zbliżamy się do osobliwości tłumaczenia. Osobliwość osiąga się, gdy najlepsi profesjonalni tłumacze poświęcają tyle samo czasu na korektę tłumaczenia wykonanego przez tłumaczenie maszynowe (MT), co na korektę tłumaczenia wykonanego przez innych tłumaczy.
W medycynie przełamywanie barier językowych jest jeszcze bardziej skuteczne niż w innych dziedzinach. Bariery te uniemożliwiają pacjentom jasne zrozumienie ich stanu klinicznego, utrudniając im tym samym prawidłowe stosowanie niezbędnej terapii. Ponadto bariery te utrudniają, jeśli nie uniemożliwiają, uzyskanie przez lekarzy wymaganej zgody na opiekę i ograniczenie danych i informacji potrzebnych do diagnozowania i badań. Obecnie wiele większych instytucji opieki zdrowotnej oferuje usługi tłumacza, ale wiążą się one ze znacznymi kosztami. Tak więc większość organizacji w sektorze medycznym nadal polega na mediatorach kulturowych lub rozwiązaniach DIY, takich jak aplikacje na smartfony. Pandemia Covid19 sprawiła, że potrzeba rozwiązania tego problemu stała się ważniejsza niż kiedykolwiek. Według Komisji Europejskiej1pandemia zwiększyła zapotrzebowanie na tłumaczenia o 49% w branży medycznej. Na szczęście postęp technologiczny popycha społeczność opieki zdrowotnej do spojrzenia na tłumaczenie maszynowe jako sposób na pokonanie barier językowych, a uniwersalne narzędzia komunikacji są wystarczająco blisko, aby zapewnić równe wsparcie.
Oczekujemy, że tłumaczenie maszynowe będzie miało radykalnie pozytywny wpływ na branżę opieki zdrowotnej. Potencjalne zastosowania są w trzech głównych obszarach:
– Tłumaczenie informacji dla ogółu
Tłumaczenie specjalistycznych publikacji, takich jak artykuły naukowe, patenty i raporty o chorobach. Zapewni to dostęp do globalnych badań naukowych i rzeczywistych danych (np. badań klinicznych i odkrywania leków).
– Bezproblemowa komunikacja z lekarzem i gromadzenie informacji zwrotnych od pacjentów, nawet z dyskusji odbywających się w mediach społecznościowych wśród Here, możemy połączyć MT z automatycznym rozpoznawaniem mowy (ASR) i technologiami text to speech (TTS), aby wspierać język mówiony.
Jednak tłumaczenie maszynowe będzie działać dobrze w opiece zdrowotnej tylko wtedy, gdy zapewni tłumaczenia tak dobre, jak te wykonane przez profesjonalistów tłumaczeniowych. W Translated monitorujemy jakość MT od 2011 roku, a ostatnio zdecydowaliśmy się wykorzystać ogromną ilość zebranych danych, aby zmierzyć, jak daleko jesteśmy od zapewnienia tłumaczenia maszynowego wysokiej jakości. Kiedy osiągniemy osobliwość w tłumaczeniu, możemy zintegrować automatyczne tłumaczenie w czasie rzeczywistym w prawie każdym de vice po bardzo przystępnych kosztach.
Krótka historia tłumaczenia maszynowego
Pojęcie automatycznego tłumaczenia zostało po raz pierwszy wspomniane w IXwieku , kiedy arabski kryptograf wprowadził techniki systematycznego tłumaczenia języka, które są niezwykle istotne. Jednak pierwsza publiczna demonstracja tłumaczenia maszynowego odbyła się w 1954 r. w Stanach Zjednoczonych3. Był to niewielki eksperyment, ale zachęcił badaczy do pójścia naprzód. Wczesne systemy opierały się na dwujęzycznych słownikach i regułach określających, jak tłumaczyć słowa lub frazy z języka źródłowego na język docelowy. Następnie opracowano podejście statystyczne: analizując duże ilości tłumaczeń ludzkich, maszyny zaczęły przewidywać równoważność frazy w języku docelowym. Podejście polegające na uczeniu się wzorców i prognozowaniu wzorców doprowadziło do powstania pierwszej wersji Google Translate na początku 2000 roku.
Dziś Google Translate i najbardziej zaawansowane silniki tłumaczenia maszynowego polegają na modelach sieci neuronowych opartych na głębokim uczeniu się, aby uczyć się i przewidywać wyniki końcowe. Jest to głębsza, bardziej niezawodna forma wykrywania i prognozowania wzorców. W tego rodzaju systemie tłumaczenie jest wytwarzane przez model pojedynczej sekwencji przeszkolony do przewidywania jednego słowa na raz, biorąc pod uwagę całe zdanie źródłowe i tłumaczenie, które zostało już dostarczone.
W 2017 roku konsorcjum złożone z Translated, Fondazione Bruno Kessler, University of Edinburgh i TAUS wprowadziło pierwsze adaptacyjne tłumaczenie maszynoweModernMT4. Początkowo był to projekt badawczy wspierany przez Unię Europejską,5 który później stał się oprogramowaniem open source i usługą komercyjną obsługiwaną przez Translated. W tym nowym modelu MT uczy się w czasie rzeczywistym na podstawie informacji zwrotnych od tłumacza bez przekwalifikowania modelu tłumaczenia. Pomysł adaptacyjnego tłumaczenia maszynowego pochodzi z poprzedniego projektu badawczego przeprowadzonego przez Translated, Fondazione Bruno Kessler, Uniwersytet w Edynburgu i Uniwersytet w Le Mans, ponownie sponsorowanego przez UnięEuropejską6. Pierwotnym pomysłem było stworzenie narzędzia do edycji wyników tłumaczenia maszynowego i zarządzania przepływami pracy lokalizacji. Celem badań był system MT, który mógł uczyć się z korekt tłumaczy i automatycznie poprawiać się w czasie. Komponent MT rozwiązania został później oddzielony, aby skupić się na narzędziu do edycji, które ostatecznie zostało wydane jako oprogramowanie open source w 2014 roku. Komisja Europejska umieściła projekt wśród projektów o największym potencjale innowacyjności finansowanych z Siódmego Programu Ramowego. Translated udoskonalił prototyp badawczy i stworzył komercyjną wersję Matecat, darmowego7narzędzia do tłumaczenia wspomaganego komputerowo i oprogramowania do edycji MT, które firma przyjęła jako wyłączne narzędzie produkcyjne. Dzięki Matecat i ModernMT Translated mocno naciska na idealną symbiozę między ludzką kreatywnością a inteligencją maszynową: usuwając zbędne zadania, sztuczna inteligencja pozwala profesjonalistom skupić się na niuansach języka, poprawiając jakość tłumaczenia. Ta synergia daje lingwistom lepsze sugestie, podczas gdy MT wciąż się uczy. Razem stają się bardziej wydajne, zdolne do adaptacji i opłacalne każdego dnia.
O procesie i zebranych danych
W 2011 roku firma Translated ustandaryzowała i ustaliła wysoce wiarygodny wskaźnik, aby dokładnie ocenić jakość MT. Nazywamy to Time to Edit (TTE): jest to średni czas na słowo wymagany przez najlepszych profesjonalnych tłumaczy do sprawdzenia i skorygowania sugerowanych tłumaczeń MT. Umożliwia to przejście z automatycznych szacunków nadal stosowanych w branży na pomiary wysiłku poznawczego człowieka, przypisując ocenę jakości osobom tradycyjnie odpowiedzialnym za zadanie: profesjonalnym tłumaczom. Śledzimy Time to Edit od prawie dekady, zbierając ponad 2 miliardy edycji zdań skutecznie przetłumaczonych przez 136 000 profesjonalnych tłumaczy na całym świecie pracujących w wielu dziedzinach tematycznych, od literatury po tłumaczenia techniczne, w tym w dziedzinach, w których MT wciąż walczy, takich jak transkrypcja mowy. Lingwiści zostali wybrani do konkretnych zadań, które wykonali przy użyciu zastrzeżonej sztucznej inteligencji o8nazwie TRank, która gromadzi dane dotyczące wydajności pracy i kwalifikacji ponad 300 000 freelancerów, którzy pracowali z firmą w ciągu ostatnich dwóch dekad. Sztuczna inteligencja bierze pod uwagę ponad 30 czynników, w tym dopasowanie CV, jakość, terminowość dostaw, dostępność i wiedzę specjalistyczną w obszarach tematycznych związanych z domeną.
Pracując w Matecat, tłumacze sprawdzają i poprawiają sugestie tłumaczeniowe dostarczone przez wybrany przez nich silnik MT. Dane zostały początkowo zebrane za pomocą statystycznego MT Google (2015-2016), następnie neuronowego MT Google, a ostatnio adaptacyjnego neuronowego MT Modern MT, wprowadzonego w 2018 roku, który szybko stał się preferowanym wyborem wśród prawie wszystkich naszych tłumaczy. Translated zbiera dane o średnim czasie ciągłej edycji słowa od ponad siedmiu lat.
Aby udoskonalić próbkę, rozważaliśmy tylko następujące kwestie:
– Wykonane prace wykonane na wysokim poziomie jakościowym.
– Zdania z sugestiami MT, które nie pasowały do baz danych wcześniej przetłumaczonych segmentów tekstu.
– Praca, w której język docelowy ma dużą ilość dostępnych danych wraz ze sprawdzoną wydajnością MT (angielski, francuski, niemiecki, hiszpański, włoski i portugalski).
Z powstałej puli zdań usunęliśmy:
Zdania, które nie otrzymały żadnych zmian, ponieważ nie dostarczyły informacji o TTE, oraz zdania, których edycja zajęła więcej niż 10 sekund na słowo, ponieważ sugerują przerwy i/lub niezwykle dużą złożoność. To udoskonalenie było wymagane, aby umożliwić porównanie TTE w wielu
– Prace nad adaptacją do locale, czyli tłumaczeniami między wariantami jednego języka (np. brytyjskiego angielskiego na amerykański angielski), ponieważ nie są one reprezentatywne dla problemu w
– Duże zadania dla klientów, ponieważ wykorzystują wysoce spersonalizowane modele językowe i pamięci tłumaczeniowe, w których wydajność TTE jest znacznie lepsza niż średnia.
Na czas edycji mają wpływ dwie główne zmienne inne niż jakość MT: ewolucja narzędzia do edycji i jakość dostarczana przez tłumacza. Wpływ tych dwóch czynników można uznać za nieistotny, biorąc pod uwagę długoterminowy trend poprawy, który zaobserwowaliśmy.
Zaskakujący liniowy trend zbliżający się do osobliwości w tłumaczeniu
Po wykreśleniu graficznym dane TTE wykazują zaskakująco liniowy trend. Nasza wstępna hipoteza, aby to wyjaśnić, jest taka, że każda jednostka postępu do oddziałów zlikwidowania luki jakościowej wymaga wykładniczo więcej zasobów niż poprzednia jednostka, i odpowiednio wdrażamy te zasoby: moc obliczeniową (podwajając się co dwa lata), dostępność danych (liczba słów przetłumaczonych w fałdach przy złożonym rocznym tempie wzrostu 6,2% według Nimdzi Insights) i wydajność algorytmów uczenia maszynowego (obliczenia potrzebne do szkolenia, 44x poprawa od 2012-2019, zgodnie z OpenAI 9.
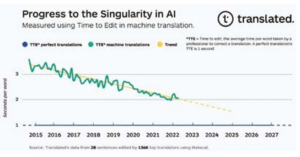
Ryc. 1.
Jak blisko jesteśmy przełamania barier językowych
Jeśli postęp w jakości tłumaczenia maszynowego będzie kontynuowany zgodnie z obecnym trendem, za około sześć lat najlepsi profesjonalni tłumacze będą spędzać tyle samo czasu na korygowaniu tłumaczeń wykonywanych przez tłumaczenie maszynowe, co na korygowaniu tłumaczeń wykonywanych przez innych tłumaczy. Dokładna data, kiedy osiągniemy osobliwość w tłumaczeniu, może się różnić, ale trend jest jasny. Dlatego jesteśmy blisko zapewnienia w czasie rzeczywistym, uniwersalnych, dostępnych narzędzi tłumaczeniowych, które przełamią bariery językowe, pozwalając nam poprawić wyniki zdrowotne klientów, zmniejszając ryzyko śmierci.
Z punktu widzenia badań dowody dostarczone przez Translated na temat postępów w jakości MT są prawdopodobnie najbardziej przekonującym dowodem sukcesu na dużą skalę, jaki można zaobserwować zarówno w społeczności MT, jak i AI w ogóle. Rzeczywiście, wielu badaczy AI uważa, że rozwiązanie problemu tłumaczenia językowego jest równoznaczne z wytworzeniem sztucznej inteligencji ogólnej (AGI). W ten sposób odkrycie Translated po raz pierwszy w historii określiło szybkość, z jaką zbliżamy się do osobliwości sztucznej inteligencji, hipotetycznego przyszłego punktu w czasie, w którym sztuczna inteligencja przewyższa ludzką inteligencję.