The article has been translated automatically. Show original:
The article has been translated automatically. Show original:
Наличие универсальных коммуникационных инструментов и их влияние на здравоохранение
Предоставление каждому человеку возможности понимать и быть понятым на своем языке является одной из наиболее важных задач для человечества. Достижение этой цели будет способствовать беспрецедентному сотрудничеству между людьми. Представьте себе, например, если бы научные исследования были доступны на языке каждого исследователя, как только они были опубликованы. Мы недалеко от этого, о чем свидетельствуют исследования, которые мы проводим в Translated, глобальном поставщике языковых услуг и пионере переводческих услуг на основе ИИ. Это новаторское исследование было представлено на последней ежегодной конференции Ассоциации машинного перевода в Америке (AMTA) в Орландо.
Анализируя правки, сделанные 136 000 лучших профессиональных переводчиков в мире до 2 миллиардов предложений, обработанных программным обеспечением автоматического перевода (машинный перевод), впервые в истории мы смогли количественно оценить скорость, с которой мы приближаемся к сингулярности в переводе. Сингулярность достигается, когда лучшие профессиональные переводчики тратят то же время на исправление перевода, выполненного машинным переводом (MT), что и на исправление перевода, выполненного их коллегами.
В медицинской сфере преодоление языковых барьеров еще более эффективно, чем в других областях. Эти барьеры мешают пациентам четко понимать свои клинические состояния, что затрудняет им правильное соблюдение необходимой терапии. Кроме того, эти барьеры затрудняют, если не делают невозможным, получение врачами необходимого согласия на уход и ограничивают данные и информацию, необходимые для диагностики и исследований. Сегодня многие крупные медицинские учреждения предлагают услуги устных переводчиков, но это требует значительных затрат. Таким образом, большинство организаций в медицинском секторе по-прежнему полагаются на культурных посредников или DIY-решения, такие как приложения для смартфонов. Пандемия Covid19 сделала необходимость решения этой проблемы более важной, чем когда-либо. По данным Европейской комиссии1, пандемия увеличила спрос на перевод на 49% в отрасли здравоохранения. К счастью, технологические достижения подталкивают медицинское сообщество к тому, чтобы рассматривать машинный перевод как средство преодоления языковых барьеров, а универсальные средства коммуникации достаточно близки, чтобы обеспечить поддержку.
Мы ожидаем, что машинный перевод окажет радикальное положительное влияние на отрасль здравоохранения. Потенциальные приложения находятся в трех основных областях:
— Перевод информации для общего
— Перевод специализированных публикаций, таких как научные статьи, патенты и отчеты о заболеваниях. Это обеспечит доступ к глобальным исследованиям и реальным данным (например, клинические испытания и открытие лекарств).
— Беспрепятственное общение врача с пациентом и сбор отзывов пациентов, даже из обсуждений, происходящих в социальных сетях среди Здесь, мы можем объединить MT с технологиями автоматического распознавания речи (ASR) и преобразования текста в речь (TTS) для поддержки разговорного языка.
Тем не менее, машинный перевод будет хорошо работать в здравоохранении только тогда, когда он обеспечивает переводы так же хорошо, как профессионалы перевода. В Translated мы отслеживаем качество MT с 2011 года, и недавно мы решили использовать огромный объем данных, которые мы собрали, чтобы измерить, насколько мы далеки от обеспечения машинного перевода человеческого качества. Когда мы достигаем сингулярности в переводе, мы можем интегрировать автоматический перевод в реальном времени почти в каждом типе по очень доступной цене.
Краткая история машинного перевода
Концепция автоматического перевода была впервые упомянута в 9веке , когда арабский криптограф представил методы систематического перевода языка, которые, невероятно, все еще2актуальны. Тем не менее, первая публичная демонстрация машинного перевода была проведена в 1954 году в Соединенных3Штатах. Это был небольшой эксперимент, но он побудил исследователей двигаться вперед. Ранние системы полагались на двуязычные словари и правила, указывающие, как переводить слова или фразы с исходного языка на целевой язык. Затем был разработан статистический подход: анализируя большие объемы человеческих переводов, машины начали предсказывать эквивалентность фразы на целевом языке. Подход, основанный на изучении шаблонов и прогнозировании шаблонов, привел к появлению первой версии Google Translate в начале 2000-х годов.
Сегодня Google Translate и самые передовые механизмы машинного перевода полагаются на модели нейронных сетей на основе глубокого обучения для изучения и прогнозирования конечных результатов. Это более глубокая и надежная форма обнаружения и прогнозирования паттернов. В такой системе перевод производится с помощью модели с одной последовательностью, обученной предсказывать одно слово за раз, учитывая все исходное предложение и перевод, который уже был предоставлен.
В 2017 году консорциум, состоящий из Translated, Фонда Бруно Кесслера, Эдинбургского университета и TAUS, представил первый адаптивный машинный перевод ModernMT4. Первоначально это был исследовательский проект, поддерживаемый Европейским Союзом, который5 позже стал программным обеспечением с открытым исходным кодом и коммерческим сервисом на базе Translated. В этой новой модели MT учится в режиме реального времени на основе корректирующей обратной связи переводчика без переобучения модели перевода. Идея адаптивного машинного перевода восходит к предыдущему исследовательскому проекту, проведенному Translated, Фондом Бруно Кесслера, Эдинбургским университетом и Университетом Ле-Мана, спонсируемым снова Европейским союзом6. Первоначальная идея заключалась в создании инструмента для редактирования результатов машинного перевода и управления рабочими процессами локализации. Целью исследования была система MT, которая могла бы учиться на исправлениях переводчиков и автоматически улучшаться с течением времени. Компонент MT решения был позже отделен, чтобы сосредоточиться на инструменте редактирования, который был наконец выпущен как программное обеспечение с открытым исходным кодом в 2014 году. Европейская комиссия включила проект в число проектов с самым высоким потенциалом для инноваций, финансируемых Седьмой рамочной программой. Translated усовершенствовал исследовательский прототип и создал коммерческую версию, Matecat, бесплатную7для использования компьютерного инструмента перевода и программного обеспечения для редактирования MT, которое компания приняла в качестве своего эксклюзивного производственного инструмента. С Matecat и ModernMT Translated упорно стремится к идеальному симбиозу между человеческим творчеством и машинным интеллектом: удаляя избыточные задачи, ИИ позволяет профессионалам сосредоточиться на нюансах языка, улучшая качество перевода. Эта синергия дает лингвистам лучшие предложения, в то время как MT продолжает учиться. Вместе они становятся более эффективными, способными адаптироваться и экономически эффективными каждый день.
О процессе и собранных данных
В 2011 году Translated стандартизировала и остановилась на высоконадежной метрике для точной оценки качества MT. Мы называем это Time to Edit (TTE): это среднее время на слово, необходимое лучшим профессиональным переводчикам для проверки и исправления предлагаемых переводов MT. Это позволяет перейти от автоматизированных оценок, все еще используемых в отрасли, к измерениям когнитивных усилий человека, переназначая оценку качества лицам, традиционно ответственным за задачу: профессиональным переводчикам. Мы отслеживаем время редактирования в течение почти десятилетия, собрав более 2 миллиардов правок предложений, эффективно переведенных 136 000 профессиональных переводчиков по всему миру, работающих в различных предметных областях, от литературы до технического перевода, включая области, в которых MT все еще борется, такие как транскрипция речи. Лингвисты были отобраны для конкретных работ, которые они выполнили, используя запатентованный ИИ под8названием TRank8, который собирает данные о производительности труда и квалификации более 300 000 фрилансеров, которые работали с компанией за последние два десятилетия. AI учитывает более 30 факторов, включая соответствие резюме, качество работы, своевременность доставки, доступность и опыт в конкретных предметных областях.
Работая в Matecat, переводчики проверяют и исправляют предложения по переводу, предоставляемые движком MT по своему выбору. Данные были первоначально собраны с помощью статистического MT Google (2015-2016), затем нейронного MT Google, а совсем недавно с помощью адаптивного нейронного MT Modern MT, представленного в 2018 году, который быстро стал предпочтительным выбором среди почти всех наших переводчиков. Translated собирает среднее время для непрерывного редактирования слова в течение более семи лет.
Для уточнения выборки мы рассмотрели только следующее:
– Выполненные работы поставлены на высоком уровне качества.
– Предложения с подсказками MT, которые не совпадали с базами данных ранее переведенных сегментов текста.
– Рабочие места, в которых целевой язык имеет огромный объем данных, доступных наряду с доказанной эффективностью MT (английский, французский, немецкий, испанский, итальянский и португальский).
Из полученного пула предложений мы удалили:
— Предложения, которые не получили никаких изменений, поскольку они не предоставляли информацию о TTE, и предложения, которые редактировались более 10 секунд за слово, поскольку они предполагают перерывы и/или необычно высокую сложность. Это уточнение потребовалось для того, чтобы сделать возможным сравнение TTE по нескольким
— Работа над адаптацией к языку, т.е. переводы между вариантами одного языка (например, британский английский на американский английский), поскольку они не являются репрезентативными для проблемы в
— Большие рабочие места клиентов, поскольку они используют высоко настроенные языковые модели и память переводов, в которых производительность TTE намного лучше, чем в среднем.
На время редактирования влияют две основные переменные, отличные от качества MT: эволюция инструмента редактирования и качество, предоставляемое переводчиком. Влияние этих двух факторов можно считать незначительным при рассмотрении долгосрочной тенденции улучшения, которую мы наблюдали.
Удивительная линейная тенденция приближается к сингулярности в переводе
При графическом построении данные TTE показывают удивительно линейную тенденцию. Наша первоначальная гипотеза, объясняющая это, заключается в том, что каждая единица прогресса в устранении разрыва в качестве, требует экспоненциально больше ресурсов, чем предыдущая единица, и мы, соответственно, развертываем эти ресурсы: вычислительная мощность (удваивается каждые два года), доступность данных (количество слов, переведенных в складки при совокупных годовых темпах роста 6,2% по данным Nimdzi Insights) и эффективность алгоритмов машинного обучения (вычисления, необходимые для обучения, улучшение в 44 раза с 2012-2019 годов, по данным OpenAI 9.
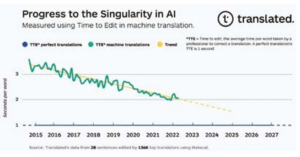
Рис. 1.
Вывод: насколько мы близки к преодолению языковых барьеров
Если прогресс в качестве машинного перевода будет продолжаться в соответствии с текущей тенденцией, примерно через шесть лет лучшие профессиональные переводчики будут тратить то же время на исправление перевода, выполненного машинным переводом, что и на исправление перевода, выполненного их коллегами. Точная дата, когда мы достигнем сингулярности в переводе, может варьироваться, но тенденция ясна. Поэтому мы близки к тому, чтобы предоставить в режиме реального времени универсальные и доступные инструменты перевода, которые сломают языковые барьеры, что позволит нам улучшить показатели здоровья клиентов и снизить риск смерти.
С исследовательской точки зрения, доказательства, предоставленные Translated о прогрессе в качестве МТ, вполне возможно, являются наиболее убедительным доказательством успеха в масштабе, наблюдаемым как в сообществах МТ, так и в сообществах ИИ в целом. Действительно, многие исследователи ИИ считают, что решение проблемы перевода языка эквивалентно созданию искусственного общего интеллекта (AGI). Таким образом, открытие Translated впервые в истории количественно оценило скорость, с которой мы приближаемся к сингулярности в искусственном интеллекте, гипотетическому будущему, в котором искусственный интеллект выходит за рамки человеческого интеллекта.