The article has been translated automatically. Show original:
The article has been translated automatically. Show original:
Introduktion: Tillgängligheten av universella kommunikationsverktyg och deras inverkan på hälso- och sjukvården
Att låta alla förstå och bli förstådda på sitt eget språk är en av de viktigaste utmaningarna för mänskligheten. Att uppnå detta kommer att underlätta oöverträffat samarbete mellan människor. Föreställ dig till exempel om vetenskaplig forskning fanns tillgänglig på varje forskares språk så snart det publicerades. Vi är inte långt ifrån det, vilket bevisas av den forskning vi bedriver på Translated, en global leverantör av språktjänster och pionjär inom AI-drivna översättningstjänster. Denna banbrytande forskning presenterades vid den sista årliga konferensen för Association for Machine Translation in the Americas (AMTA) i Orlando.
Genom att analysera de ändringar som gjorts av 136 000 av de bästa professionella översättarna i världen till 2 miljarder meningar som bearbetats med automatisk översättningsprogramvara (maskinöversättning), kunde vi för första gången i historien kvantifiera den hastighet med vilken vi närmar oss singulariteten i översättning. Singulariteten uppnås när de bästa professionella översättarna spenderar samma tid på att korrigera en översättning som produceras av maskinöversättning (MT) som de korrigerar en som slutförts av sina kamrater.
På det medicinska området är det ännu mer effektivt att bryta språkbarriärer än på andra områden. Dessa hinder hindrar patienterna från att tydligt förstå sina kliniska tillstånd, vilket gör det svårt för dem att följa nödvändig behandling korrekt. Dessutom gör dessa hinder det svårt, om inte omöjligt, för läkare att få det samtycke som krävs för att vårda och begränsa data och information som behövs för diagnoser och forskning. Idag erbjuder många större vårdinrättningar tolktjänster, men dessa kostar mycket. Således förlitar sig de flesta organisationer inom den medicinska sektorn fortfarandepå kulturella medlare eller DIY-lösningar, till exempel smartphone-appar. Covid19-pandemin har gjort behovet av att ta itu med detta problem viktigare än någonsin. Enligt Europeiska kommissionen ökade1pandemin efterfrågan på översättning med 49% inom hälso- och sjukvårdsindustrin. Lyckligtvis driver tekniska framsteg sjukvården att titta på maskinöversättning som ett sätt att övervinna språkbarriärer, och universella kommunikationsverktyg är tillräckligt nära för att ge lika stöd.
Vi förväntar oss att maskinöversättning kommer att ha en radikal positiv inverkan på hälso- och sjukvårdsindustrin. Potentiella tillämpningar finns inom tre huvudområden:
– Översättning av information för allmänheten
– Översättning av specialistpublikationer såsom vetenskapliga artiklar, patent och sjukdomsrapporter. Detta kommer att ge tillgång till globala forskningsstudier och verkliga data (t.ex. kliniska prövningar och läkemedelsupptäckt).
– Sömlös läkarpatientkommunikation och insamling av patientåterkoppling, även från diskussioner som händer på sociala medier bland Här kan vi kombinera MT med automatisk taligenkänning (ASR) och text till tal (TTS) teknik för att stödja talat språk.
Maskinöversättning fungerar dock bara bra inom hälso- och sjukvården när den ger översättningar som är lika bra som de som görs av översättningsexperter. På Translated har vi övervakat MT-kvalitet sedan 2011, och nyligen bestämde vi oss för att använda den enorma mängd data vi har samlat in för att mäta hur långt vi är från att tillhandahålla maskinöversättning av mänsklig kvalitet. När vi når singulariteten i översättning kan vi integrera automatisk översättning i realtid i nästan varje de vice till en mycket tillgänglig kostnad.
En kort historia av maskinöversättning
Begreppet automatisk översättning nämndes för första gången på 800-talet när en 9 arabisk kryptograf introducerade tekniker för systematisk språköversättning som, otroligt nog, fortfarande är relevanta2. Men den första offentliga demonstrationen av maskinöversättning gjordes 19543USA. Det var ett litet experiment, men det uppmuntrade forskare att driva framåt. Tidiga system förlitade sig på tvåspråkiga ordböcker och regler som anger hur man översätter ord eller fraser från ett källspråk till ett målspråk. Därefter utvecklades ett statistiskt tillvägagångssätt: genom att analysera stora volymer mänskliga översättningar började maskiner förutsäga ekvivalensen av en fras på målspråket. Frasen fokuserat mönster lärande och mönster prognoser tillvägagångssätt körde den första versionen av Google Translate i början av 2000-talet.
Idag är Google Translate och de mest avancerade maskinöversättningsmotorerna beroende av djupinlärningsbaserade neurala nätverksmodeller för att lära sig och förutsäga slutresultat. Detta är en djupare, mer tillförlitlig form av mönsterdetektering och prognoser. I denna typ av system produceras översättningen av en enda sekvensmodell som är utbildad för att förutsäga ett ord i taget, med tanke på hela källmeningen och översättningen som redan har tillhandahållits.
År 2017 introducerade ett konsortium bestående av Translated, Fondazione Bruno Kessler, University of Edinburgh och TAUS den första adaptiva maskinöversättningen, ModernMT4. Det var ursprungligen ett forskningsprojekt som stöddes av Europeiska unionen och5 som senare blev programvara med öppen källkod och en kommersiell tjänst som drivs av Translated. I den nya modellen lär sig MT i realtid av översättarens korrigerande feedback utan att omskolas i översättningsmodellen. Idén om adaptiv maskinöversättning går tillbaka till ett tidigare forskningsprojekt som genomfördes av Translated, Fondazione Bruno Kessler, University of Edinburgh och Le Mans University, sponsrade igen av Europeiska6unionen. Den ursprungliga idén var att skapa ett verktyg för att redigera maskinöversättningsresultat och hantera lokaliseringsarbetsflöden. Forskningsmålet var ett MT-system som kunde lära av översättarnas korrigeringar och automatiskt förbättras med tiden. MT-komponenten i lösningen separerades senare för att fokusera på redigeringsverktyget, som slutligen släpptes som öppen källkod 2014. Europeiska kommissionen inkluderade projektet bland dem som har störst potential för innovation som finansieras av sjunde ramprogrammet. Translated förfinade ytterligare forskningsprototypen och skapade en kommersiell version,7Matecat, ett fritt att använda datorstödd översättningsverktyg och MT-redigeringsprogramvara som företaget antog som sitt exklusiva produktionsverktyg. Med Matecat och ModernMT driver Translated hårt för en perfekt symbios mellan mänsklig kreativitet och maskinintelligens: genom att ta bort överflödiga uppgifter gör AI det möjligt för proffs att fokusera på nyanserna i språket och förbättra kvaliteten på översättningen. Denna synergi ger lingvister bättre förslag medan MT fortsätter att lära sig. Tillsammans blir de mer effektiva, anpassningsbara och kostnadseffektiva varje dag.
Om processen och de insamlade uppgifterna
Under 2011 standardiserade och bestämde Translated sig för ett mycket tillförlitligt mått för att utvärdera MT-kvaliteten korrekt. Vi kallar det Time to Edit (tte): det här är den genomsnittliga tiden per ord som krävs av de bästa professionella översättarna för att kontrollera och korrigera MT föreslagna översättningar. Detta gör det möjligt att byta från automatiserade uppskattningar som fortfarande används i branschen till mätningar av mänsklig kognitiv ansträngning, omfördela kvalitetsutvärderingen till personer som traditionellt ansvarar för uppgiften: professionella översättare. Vi har spårat Time to Edit i nästan ett decennium och samlat in över 2 miljarder redigeringar på meningar som effektivt översatts av 136 000 professionella översättare över hela världen som arbetar inom flera ämnesområden, allt från litteratur till teknisk översättning och inklusive områden där MT fortfarande kämpar, till exempel tal transkription. Lingvisterna valdes för de specifika jobb de slutförde med hjälp av egenutvecklad AI som8heter TRank, som samlar arbetsprestations- och kvalifikationsdata på över 300 000 frilansare som har arbetat med företaget under de senaste två decennierna. AI överväger över 30 faktorer, inklusive CV-matchning, kvalitetsprestanda, tid leveransrekord, tillgänglighet och expertis inom domänspecifika ämnesområden.
Översättare som arbetar i Matecat kontrollerar och korrigerar översättningsförslag som tillhandahålls av den MT-motor de väljer. Uppgifterna samlades ursprungligen in med hjälp av Googles statistiska MT (2015-2016), sedan Googles neurala MT, och senast av Modern MT: s adaptiva neurala MT, som introducerades 2018, vilket snabbt blev det föredragna valet bland nästan alla våra översättare. Translated har samlat in den genomsnittliga tiden för att redigera ett ord kontinuerligt i över sju år.
För att förfina provet beaktade vi endast följande:
– Avslutade jobb levereras på en hög nivå av kvalitet.
– Meningar med MT-förslag som inte matchade från databaser med tidigare översatta textsegment.
– Jobb där målspråket har en stor mängd data tillgänglig tillsammans med bevisad MT effektivitet (engelska, franska, tyska, spanska, italienska och portugisiska).
Från den resulterande poolen av meningar tog vi bort:
Meningar som inte fick några redigeringar eftersom de inte gav information om tte och meningar som tog mer än 10 sekunder per ord som ska redigeras, eftersom de föreslår avbrott och/eller ovanligt hög komplexitet. Denna förfining krävdes för att möjliggöra TTE-jämförelse över flera
– Arbete med anpassning till språk, dvs. översättningar mellan varianter av ett enda språk (t.ex. brittisk engelska till amerikansk engelska), eftersom dessa inte är representativa för problemet vid
– Stora kundjobb, eftersom de använder mycket anpassade språkmodeller och översättningsminnen där TTE-prestanda är mycket bättre än genomsnittet.
Tid till redigering påverkas av två andra huvudvariabler än MT-kvalitet: utvecklingen av redigeringsverktyget och kvaliteten som översättaren levererar. Påverkan av dessa två faktorer kan anses försumbar när man beaktar den långsiktiga förbättringsutvecklingen som vi observerade.
En överraskande linjär trend närmar sig singulariteten i översättning
När de plottas grafiskt visar TTE-data en överraskande linjär trend. Vår första hypotes för att förklara detta är att varje enhet av framsteg till avdelningar som stänger kvalitetsgapet kräver exponentiellt mer resurser än den tidigare enheten, och vi distribuerar följaktligen dessa resurser: datorkraft (fördubbling vartannat år), datatillgänglighet (antalet ord översatta i veck med en sammansatt årlig tillväxt på 6,2% enligt Nimdzi Insights) och effektiviteten i maskininlärningsalgoritmer (beräkning som behövs för utbildning, 44x förbättring från 2012-2019, enligt OpenAI9).
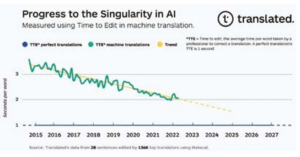
Bild 1.
Slutsats: Hur nära vi är att bryta språkbarriärer
Om framstegen i maskinöversättningskvaliteten fortsätter med den nuvarande trenden, kommer de bästa professionella översättarna om cirka sex år att spendera samma tid på att korrigera en översättning som produceras av maskinöversättning som de korrigerar en som slutförts av sina kamrater. Det exakta datumet när vi kommer att nå singulariteten i översättning kan variera en del vad, men trenden är tydlig. Vi är därför nära att kunna tillhandahålla universella, tillgängliga översättningsverktyg i realtid som kommer att bryta språkbarriärerna, så att vi kan förbättra kundernas hälsoutfall och minska risken för dödsfall.
Ur forskningssynpunkt är de bevis som Translated har tillhandahållit om framstegen i MT-kvaliteten förmodligen det mest övertygande beviset på framgång i stor skala som ses i både MT- och AI-samhällena i allmänhet. Faktum är att många AI-forskare tror att lösa språköversättningsproblemet är likvärdigt med att producera artificiell allmän intelligens (AGI). Translateds upptäckt har alltså kvantifierat, för första gången i historien, den hastighet med vilken vi närmar oss singulariteten i artificiell intelligens den hypotetiska framtida tidpunkten vid vilken artificiell intelligens överskrider mänsklig intelligens.