The article has been translated automatically. Show original:
The article has been translated automatically. Show original:
Inleiding: De beschikbaarheid van universele communicatiemiddelen en hun impact op de gezondheidszorg
Iedereen in staat stellen hun eigen taal te begrijpen en begrepen te worden, is een van de belangrijkste uitdagingen voor de mensheid. Dit zal een ongekende samenwerking tussen mensen vergemakkelijken. Stel je bijvoorbeeld voor dat wetenschappelijk onderzoek beschikbaar was in de taal van elke onderzoeker zodra het werd gepubliceerd. Daar zijn we niet ver van verwijderd, zoals blijkt uit het onderzoek dat we uitvoeren bij Translated, een wereldwijde aanbieder van taaldiensten en pionier op het gebied van AI-gedreven vertaaldiensten. Dit baanbrekende onderzoek werd gepresenteerd op de laatste jaarlijkse conferentie van de Association for Machine Translation in the Americas (AMTA) in Orlando.
Door voor het eerst in de geschiedenis de bewerkingen van 136.000 van de beste professionele vertalers ter wereld te analyseren op 2 miljard zinnen die worden verwerkt door automatische vertaalsoftware (machinevertaling), konden we de snelheid kwantificeren waarmee we de singulariteit in vertaling naderen. De singulariteit wordt bereikt wanneer de best presterende professionele vertalers dezelfde tijd besteden aan het corrigeren van een vertaling die is geproduceerd door machinevertaling (MT) als aan het corrigeren van een vertaling die is voltooid door hun collega ‘s.
Op medisch gebied heeft het doorbreken van taalbarrières nog meer impact dan op andere gebieden. Deze barrières voorkomen dat patiënten hun klinische aandoeningen duidelijk begrijpen, waardoor het voor hen moeilijk wordt om zich correct aan de noodzakelijke therapie te houden. Bovendien maken deze barrières het moeilijk, zo niet onmogelijk, voor artsen om de vereiste toestemming te verkrijgen om te zorgen en gegevens en informatie te beperken die nodig zijn voor diagnoses en onderzoek. Tegenwoordig bieden veel grotere zorginstellingen tolkdiensten aan, maar deze kosten aanzienlijk. De meeste organisaties in de medische sector vertrouwen dus nog steeds op culturele bemiddelaars of doe-het-zelf-oplossingen, zoals smartphone-apps. De Covid19-pandemie heeft de noodzaak om dit probleem aan te pakken belangrijker dan ooit gemaakt. Volgens de EuropeseCommissie1heeft de pandemie de vraag naar vertalingen in de gezondheidszorg met 49% doen toenemen. Gelukkig zijn de technologische vooruitgang duwen de gezondheidszorg om te kijken naar machinevertaling als een middel om het overwinnen van taalbarrières, en universele communicatie-instrumenten zijn dicht genoeg om ad gelijk ondersteuning te bieden.
We verwachten dat machinevertaling een radicaal positief effect zal hebben op de gezondheidszorg. Potentiële toepassingen liggen op drie hoofdgebieden:
– De vertaling van informatie voor de algemene
– De vertaling van gespecialiseerde publicaties zoals wetenschappelijke artikelen, octrooien en ziekterapporten. Dit zal toegang bieden tot wereldwijde onderzoeksstudies en gegevens uit de praktijk (bijv. klinische proeven en geneesmiddelenontdekking).
– Naadloze communicatie tussen artsen en patiënten en het verzamelen van feedback van patiënten, zelfs van discussies op sociale media tussen Here, kunnen we MT combineren met automatische spraakherkenning (ASR) en tekst-naar-spraak (TTS) -technologieën om gesproken taal te ondersteunen.
Machinevertaling zal echter alleen goed presteren in de gezondheidszorg als het vertalingen levert die net zo goed zijn als die van vertaalprofessionals. Bij Translated monitoren we sinds 2011 de MT-kwaliteit en onlangs hebben we besloten om de enorme hoeveelheid gegevens die we hebben verzameld te gebruiken om te meten hoe ver we zijn verwijderd van het leveren van machinevertalingen van menselijke kwaliteit. Wanneer we de singulariteit in vertaling bereiken, kunnen we realtime automatische vertaling integreren in bijna elke ondeugd tegen een zeer toegankelijke prijs.
Een korte geschiedenis van machinevertaling
Het concept van automatische vertaling werd voor het eerst genoemd in de9e eeuw toen een Arabische cryptograaf technieken introduceerde voor systematische taalvertaling die, ongelooflijk, nog steeds relevantzijn. De eerste openbare demonstratie van machinevertaling werd echter in 1954 in de Verenigde Statengedaan3. Het was een klein experiment, maar het moedigde onderzoekers aan om verder te gaan. Vroege systemen vertrouwden op tweetalige woordenboeken en regels waarin stond hoe woorden of zinnen uit een brontaal in een doeltaal moesten worden vertaald. Vervolgens werd een statistische benadering ontwikkeld: door het analyseren van grote hoeveelheden menselijke vertalingen begonnen machines de gelijkwaardigheid van een zin in de doeltaal te voorspellen. De frase gericht patroon leren en patroon forecasting aanpak reed de eerste versie van Google Translate in de vroege jaren 2000.
Tegenwoordig vertrouwen Google Translate en de meest geavanceerde machinevertalingsengines op op deep learning gebaseerde neurale netwerkmodellen om de uiteindelijke resultaten te leren en te voorspellen. Dit is een diepere, betrouwbaardere vorm van patroondetectie en -voorspelling. In dit soort systemen wordt de vertaling geproduceerd door een enkel sequentiemodel dat is getraind om één woord per keer te voorspellen, rekening houdend met de hele bronzin en de vertaling die al is verstrekt.
In 2017 introduceerde een consortium bestaande uit Translated, de Fondazione Bruno Kessler, de Universiteit van Edinburgh en TAUS de eerste adaptieve machinevertaling,ModernMT4. Het was aanvankelijk een onderzoeksproject gesteund door de Europese Unie5 dat later open source software en een commerciële dienst aangedreven door Translated werd. In dit nieuwe model leert MT in realtime van de correctieve feedback van de vertaler zonder het vertaalmodel opnieuw te trainen. Het idee voor adaptieve machinevertaling gaat terug tot een eerder onderzoeksproject uitgevoerd door Translated, de Fondazione Bruno Kessler, de Universiteit van Edinburgh en de Universiteit van Le Mans, opnieuw gesponsord door de Europese6.Unie Het oorspronkelijke idee was om een tool te maken om machinevertalingsresultaten te bewerken en lokalisatieworkflows te beheren. De onderzoeksdoelstelling was een MT-systeem dat kon leren van correcties van vertalers en automatisch kon verbeteren in de loop van de tijd. De MT-component van de oplossing werd later gescheiden om zich te concentreren op de bewerkingstool, die uiteindelijk in 2014 werd uitgebracht als open-source software. De Europese Commissie heeft het project opgenomen onder degenen met het hoogste innovatiepotentieel dat door het zevende kaderprogramma wordt gefinancierd. Translated heeft het onderzoeksprototype verder verfijnd en een commerciële versie gemaakt7, Matecat, een gratis te gebruiken computerondersteunde vertaaltool en MT-bewerkingssoftware die het bedrijf heeft aangenomen als zijn exclusieve productietool. Met Matecat en ModernMT streeft Translated hard naar een perfecte symbiose tussen menselijke creativiteit en machine-intelligentie: door overbodige taken te verwijderen, stelt AI professionals in staat zich te concentreren op de nuances van taal, waardoor de kwaliteit van de vertaling wordt verbeterd. Deze synergie geeft taalkundigen betere suggesties terwijl MT blijft leren. Samen worden ze elke dag efficiënter, aanpasbaarder en kosteneffectiever.
Over het proces en de verzamelde gegevens
In 2011 is Translated gestandaardiseerd en gebaseerd op een zeer betrouwbare metriek om de MT-kwaliteit nauwkeurig te evalueren. We noemen het Time to Edit (TTE): dit is de gemiddelde tijd per woord die de best presterende professionele vertalers nodig hebben om door MT voorgestelde vertalingen te controleren en te corrigeren. Dit maakt het mogelijk om over te schakelen van geautomatiseerde schattingen die nog steeds in gebruik zijn in de industrie naar metingen van menselijke cognitieve inspanningen, waarbij de kwaliteitsevaluatie wordt toegewezen aan personen die traditioneel verantwoordelijk zijn voor de taak: professionele vertalers. We volgen Time to Edit al bijna een decennium en verzamelen meer dan 2 miljard bewerkingen op zinnen die effectief zijn vertaald door 136.000 professionele vertalers over de hele wereld die op meerdere vakgebieden werken, variërend van literatuur tot technische vertaling en inclusief gebieden waarin MT nog steeds worstelt, zoals spraaktranscriptie. De taalkundigen werden geselecteerd voor de specifieke taken die ze voltooiden met behulp van gepatenteerde8AI genaamd TRank, die werkprestaties en kwalificatiegegevens verzamelt van meer dan 300.000 freelancers die de afgelopen twee decennia met het bedrijf hebben gewerkt. De AI houdt rekening met meer dan 30 factoren, waaronder cv-match, kwaliteitsprestaties, tijdige oplevering, beschikbaarheid en expertise op domeinspecifieke vakgebieden.
In Matecat controleren en corrigeren vertalers vertaalsuggesties van de MT-engine van hun keuze. De gegevens werden aanvankelijk verzameld met behulp van Google ’s statistische MT (2015-2016), vervolgens Google’ s neurale MT, en het meest recent door Modern MT ’s adaptieve neurale MT, geïntroduceerd in 2018, dat al snel de voorkeurskeuze werd onder bijna al onze vertalers. Translated verzamelt al meer dan zeven jaar de gemiddelde tijd om een woord continu te bewerken.
Om het monster te verfijnen, hebben we alleen het volgende overwogen:
– Voltooide opdrachten geleverd op een hoog kwaliteitsniveau.
– Zinnen met MT-suggesties die niet overeenkwamen met databases van eerder vertaalde tekstsegmenten.
Banen waarin de doeltaal een enorme hoeveelheid gegevens beschikbaar heeft, samen met bewezen MT-efficiëntie (Engels, Frans, Duits, Spaans, Italiaans en Portugees).
Uit de resulterende pool van zinnen hebben we verwijderd:
– Zinnen die geen bewerkingen hebben ontvangen omdat ze geen informatie over TTE gaven, en zinnen die meer dan 10 seconden per woord nodig hadden om te worden bewerkt, omdat ze duiden op onderbrekingen en/of ongewoon hoge complexiteit. Deze verfijning was nodig om TTE-vergelijking mogelijk te maken voor meerdere
– Werken aan aanpassing aan de locale, d.w.z. vertalingen tussen varianten van een enkele taal (bijv. Brits Engels naar Amerikaans Engels), aangezien deze niet representatief zijn voor het probleem bij
– Grote klantexpertises, omdat ze gebruik maken van zeer op maat gemaakte taalmodellen en vertaalgeheugens waarin de prestaties van TTE veel beter zijn dan gemiddeld.
Time to Edit wordt beïnvloed door twee andere hoofdvariabelen dan MT-kwaliteit: de evolutie van de bewerkingstool en de kwaliteit die door de vertaler wordt geleverd. De invloed van deze twee factoren kan als verwaarloosbaar worden beschouwd bij het overwegen van de langetermijntrend van verbetering die we hebben waargenomen.
Een verrassende lineaire trend die de singulariteit in vertaling benadert
Wanneer grafisch weergegeven, tonen de TTE-gegevens een verrassend lineaire trend. Onze aanvankelijke hypothese om dit uit te leggen is dat elke eenheid van vooruitgang naar afdelingen die de kwaliteitskloof dichten exponentieel meer middelen vereist dan de vorige eenheid, en we zetten dienovereenkomstig die middelen in: rekenkracht (verdubbeling om de twee jaar), beschikbaarheid van gegevens (het aantal woorden vertaald in stijgingen bij een samengestelde jaarlijkse groei van 6,2% volgens Nimdzi Insights), en de efficiëntie van algoritmen voor machine learning (berekening nodig voor training, 44x verbetering van 2012-2019, volgens OpenAI) 9.
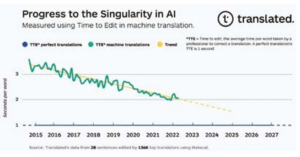
Fig. 1.
Conclusie: hoe dicht we bij het doorbreken van taalbarrières zijn
Als de vooruitgang in de kwaliteit van machinevertalingen zich doorzet met de huidige trend, zullen de best presterende professionele vertalers in ongeveer zes jaar dezelfde tijd besteden aan het corrigeren van een vertaling die is geproduceerd door machinevertaling als aan het corrigeren van een vertaling die is voltooid door hun collega ‘s. De exacte datum waarop we de singulariteit in vertaling zullen bereiken, kan variëren, maar de trend is duidelijk. We zijn daarom bijna in staat om realtime, universele, toegankelijke vertaalhulpmiddelen te bieden die de taalbarrières doorbreken, waardoor we de gezondheidsresultaten van klanten kunnen verbeteren en het risico op overlijden kunnen verlagen.
Vanuit het oogpunt van onderzoek is het bewijs dat Translated heeft geleverd over de vooruitgang in MT-kwaliteit waarschijnlijk het meest overtuigende bewijs van succes op grote schaal in zowel de MT- als AI-gemeenschappen in het algemeen. Sterker nog, veel AI-onderzoekers denken dat het oplossen van het vertaalprobleem gelijk staat aan het produceren van kunstmatige algemene intelligentie (AGI). De ontdekking van Translated heeft dus voor het eerst in de geschiedenis de snelheid gekwantificeerd waarmee we de singulariteit in kunstmatige intelligentie naderen, het hypothetische toekomstige punt in de tijd waarop kunstmatige intelligentie de menselijke intelligentie overstijgt.