The article has been translated automatically. Any images and tables cited in the articles can be found by downloading the magazine issue in PDF format. Show original:
The article has been translated automatically. Any images and tables cited in the articles can be found by downloading the magazine issue in PDF format. Show original:
Introduktion: Tilgængeligheden af universelle kommunikationsværktøjer og deres indvirkning på sundhedsvæsenet
At give alle mulighed for at forstå og blive forstået på deres eget sprog er en af de største udfordringer for menneskeheden. At opnå dette vil lette hidtil uset samarbejde mellem mennesker. Forestil dig for eksempel, hvis videnskabelig forskning var tilgængelig på hver forskers sprog, så snart det blev offentliggjort. Vi er ikke langt fra det, som det fremgår af den forskning, vi udfører hos Translated, en global sprogserviceudbyder og pioner inden for AI-drevne oversættelsestjenester. Denne banebrydende forskning blev præsenteret på den sidste årlige konference i Association for Machine Translation in the Americas (AMTA) i Orlando.
Ved at analysere redigeringer foretaget af 136.000 af de bedste professionelle oversættere i verden til 2 milliarder sætninger behandlet af automatisk oversættelse software (maskinoversættelse), for første gang i historien, var vi i stand til at kvantificere den hastighed, hvormed vi nærmer singularitet i oversættelse. Singulariteten nås, når de bedste professionelle oversættere bruger samme tid på at korrigere en oversættelse produceret af maskinoversættelse (MT), som de korrigerer en afsluttet af deres jævnaldrende.
På det medicinske område er det endnu mere effektivt at bryde sprogbarrierer end på andre områder. Disse barrierer forhindrer patienterne i klart at forstå deres kliniske tilstande, hvilket gør det vanskeligt for dem at overholde den nødvendige behandling korrekt. Desuden gør disse barrierer det vanskeligt, om ikke umuligt, for læger at opnå det nødvendige samtykke til pleje og begrænse data og oplysninger, der er nødvendige for diagnoser og forskning. I dag tilbyder mange større sundhedsinstitutioner tolketjenester, men disse koster meget. Således er de fleste organisationer i den medicinske sektor stadig afhængige af kulturelle mæglere eller DIY-løsninger, såsom smartphone-apps. Covid19-pandemien har gjort behovet for at løse dette problem vigtigere end nogensinde. Ifølge Europa-Kommissionen1 øgede1pandemien efterspørgslen efter oversættelse med 49% i sundhedssektoren. Heldigvis skubber teknologiske fremskridt sundhedsvæsenet til at se på maskinoversættelse som et middel til at overvinde sprogbarrierer, og universelle kommunikationsværktøjer er tæt nok til at give lige støtte.
Vi forventer, at maskinoversættelse vil have en radikal positiv indvirkning på sundhedssektoren. Potentielle anvendelser er inden for tre hovedområder:
– Oversættelse af oplysninger for den generelle
– Oversættelse af specialiserede publikationer såsom videnskabelige papirer, patenter og sygdomsrapporter. Dette vil give adgang til globale forskningsundersøgelser og data fra den virkelige verden (f.eks. kliniske forsøg og lægemiddelopdagelse).
– Problemfri læge patient kommunikation og indsamling af patient feedback indsamling, selv fra diskussioner, der sker på sociale medier blandt Her kan vi kombinere MT med automatisk talegenkendelse (ASR) og tekst til tale (TTS) teknologier til at understøtte talt sprog.
Men maskinoversættelse fungerer kun godt i sundhedssektoren, når den leverer oversættelser, der er lige så gode som dem, der udføres af oversættelsesfolk. Hos Translated har vi overvåget MT-kvalitet siden 2011, og for nylig besluttede vi at bruge den enorme mængde data, vi har indsamlet, til at måle, hvor langt vi er fra at levere maskinoversættelse af menneskelig kvalitet. Når vi når singulariteten i oversættelse, kan vi integrere realtids automatisk oversættelse i næsten alle de vice til en meget tilgængelig pris.
En kort historie om maskinoversættelse
Begrebet automatisk oversættelse blev nævnt for første gang i det 9.århundrede , da en arabisk kryptograf introducerede teknikker til systematisk sprogoversættelse, der er utroligt stadigrelevante2. Men den første offentlige demonstration af maskinoversættelse blev udført i 19543USA. Det var et lille eksperiment, men det opfordrede forskere til at skubbe fremad. Tidlige systemer var afhængige af tosprogede ordbøger og regler, der angav, hvordan man oversætter ord eller sætninger fra et kildesprog til et målsprog. Dernæst blev der udviklet en statistisk tilgang: Ved at analysere store mængder menneskelige oversættelser begyndte maskiner at forudsige ækvivalensen af en sætning på målsproget. Sætningen fokuseret mønster læring og mønster prognoser tilgang kørte den første version af Google Translate i begyndelsen af 2000’erne.
I dag er Google Translate og de mest avancerede maskinoversættelsesmotorer afhængige af deep learning-baserede neurale netværksmodeller til at lære og forudsige endelige output. Dette er en dybere, mere pålidelig form for mønsterdetektion og prognoser. I denne form for system, er oversættelsen produceret af en enkelt sekvens model uddannet til at forudsige et ord ad gangen, i betragtning af hele kilden sætning og oversættelse, der allerede er blevet leveret.
I 2017 introducerede et konsortium bestående af Translated, Fondazione Bruno Kessler, University of Edinburgh og TAUS den første adaptive maskinoversættelse,ModernMT4. Det var oprindeligt et forskningsprojekt støttet af EU,5 der senere blev open source-software og en kommerciel tjeneste drevet af Translated. I denne nye model lærer MT i realtid af oversætterens korrigerende feedback uden at omskole oversættelsesmodellen. Ideen til adaptiv maskinoversættelse går tilbage til et tidligere forskningsprojekt udført af Translated, Fondazione Bruno Kessler, University of Edinburgh og Le Mans University, sponsoreret igen af6EU. Den oprindelige idé var at oprette et værktøj til at redigere maskinoversættelsesresultater og administrere lokaliseringsarbejdsgange. Forskningsmålet var et MT-system, der kunne lære af oversætternes rettelser og automatisk forbedres over tid. MT-komponenten i løsningen blev senere adskilt for at fokusere på redigeringsværktøjet, som endelig blev udgivet som open source-software i 2014. Europa-Kommissionen har inkluderet projektet blandt dem, der har det største potentiale for innovation finansieret af det syvende rammeprogram. Translated videreudviklede forskningsprototypen og skabte en kommerciel version, Matecat7, et gratis at bruge computerassisteret oversættelsesværktøj og MT-redigeringssoftware, som virksomheden vedtog som sit eksklusive produktionsværktøj. Med Matecat og ModernMT presser Translated hårdt på for en perfekt symbiose mellem menneskelig kreativitet og maskinintelligens: Ved at fjerne overflødige opgaver giver AI fagfolk mulighed for at fokusere på sprogets nuancer og forbedre oversættelsens kvalitet. Denne synergi giver sprogforskere bedre forslag, mens MT fortsætter med at lære. Sammen bliver de mere effektive, tilpasningsdygtige og omkostningseffektive hver dag.
Om processen og de indsamlede data
I 2011 standardiserede og afgjorde Translated en meget pålidelig måling for at evaluere MT-kvaliteten nøjagtigt. Vi kalder det Time to Edit (tte): Dette er den gennemsnitlige tid per ord, der kræves af de bedste professionelle oversættere til at kontrollere og rette MT foreslåede oversættelser. Dette gør det muligt at skifte fra automatiserede estimater, der stadig er i brug i branchen, til målinger af menneskelig kognitiv indsats, og omfordele kvalitetsvurderingen til personer, der traditionelt er ansvarlige for opgaven: professionelle oversættere. Vi har sporet Time to Edit i næsten et årti og indsamlet over 2 milliarder redigeringer af sætninger, der effektivt er oversat af 136.000 professionelle oversættere over hele verden, der arbejder på tværs af flere fagområder, lige fra litteratur til teknisk oversættelse og herunder områder, hvor MT stadig kæmper, såsom taletranskription. Sprogforskerne blev udvalgt til de specifikke job, de afsluttede ved hjælp af proprietær AI8kaldet TRank, som indsamler data om arbejdsresultater og kvalifikationer på over 300.000 freelancere, der har arbejdet med virksomheden i de sidste to årtier. AI overvejer over 30 faktorer, herunder CV-match, kvalitetspræstation, leveringstid, tilgængelighed og ekspertise inden for domænespecifikke fagområder.
Ved at arbejde i Matecat kontrollerer oversættere og korrigerer oversættelsesforslag fra MT-motoren efter eget valg. Dataene blev oprindeligt indsamlet ved hjælp af Googles statistiske MT (2015-2016), derefter Googles neurale MT, og senest af Modern MT’s adaptive neurale MT, der blev introduceret i 2018, som hurtigt blev det foretrukne valg blandt næsten alle vores oversættere. Translated har indsamlet den gennemsnitlige tid til at redigere et ord kontinuerligt i over syv år.
For at forbedre prøven overvejede vi kun følgende:
– Afsluttede job leveret på et højt kvalitetsniveau.
– Sætninger med MT forslag, der ikke havde nogen match fra databaser af tidligere oversatte segmenter af tekst.
– Job, hvor målsproget har en stor mængde data til rådighed sammen med bevist MT effektivitet (engelsk, fransk, tysk, spansk, italiensk og portugisisk).
Fra den resulterende pulje af sætninger fjernede vi:
– Sætninger, der ikke modtog nogen redigeringer, da de ikke gav oplysninger om TTE, og sætninger, der tog mere end 10 sekunder pr. Ord, der skal redigeres, da de foreslår afbrydelser og/eller usædvanlig høj kompleksitet. Denne raffinement var nødvendig for at gøre TTE sammenligning mulig på tværs af flere
– Arbejde med tilpasning til sprog, dvs. oversættelser mellem varianter af et enkelt sprog (f.eks. britisk engelsk til amerikansk engelsk), da disse ikke er repræsentative for problemet ved
– Store kundejob, da de anvender meget tilpassede sprogmodeller og oversættelseshukommelser, hvor TTE-ydelsen er langt bedre end gennemsnittet.
Tid til redigering påvirkes af to andre hovedvariabler end MT-kvalitet: udviklingen af redigeringsværktøjet og kvaliteten leveret af oversætteren. Påvirkningen af disse to faktorer kan betragtes som ubetydelig i betragtning af den langsigtede tendens til forbedring, vi observerede.
En overraskende lineær tendens nærmer sig singulariteten i oversættelse
Når de tegnes grafisk, viser TTE-dataene en overraskende lineær tendens. Vores indledende hypotese til at forklare dette er, at hver enhed af fremskridt til afdelinger lukning af kvalitetsgabet kræver eksponentielt flere ressourcer end den tidligere enhed, og vi implementerer derfor disse ressourcer: computerkraft (fordobling hvert andet år), datatilgængelighed (antallet af ord oversat i folder med en sammensat årlig vækstrate på 6,2% ifølge Nimdzi Insights) og effektiviteten af maskinindlæringsalgoritmer (beregning nødvendig for træning, 44x forbedring fra 2012-2019, ifølge OpenAI9.
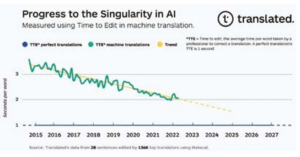
Figur 1.
Konklusion: Hvor tæt er vi på at bryde sprogbarrierer
Hvis fremskridtene i maskinoversættelseskvaliteten fortsætter med den nuværende tendens, vil de bedste professionelle oversættere om ca. seks år bruge samme tid på at korrigere en oversættelse, der er produceret af maskinoversættelse, som de korrigerer en, der er gennemført af deres jævnaldrende. Den nøjagtige dato, hvor vi vil nå singulariteten i oversættelse, kan variere noget, men tendensen er klar. Vi er derfor tæt på at kunne levere universelle, tilgængelige oversættelsesværktøjer i realtid, der vil bryde sprogbarrierer, hvilket giver os mulighed for at forbedre kundernes sundhedsresultater og reducere risikoen for død.
Fra et forskningsmæssigt synspunkt er den dokumentation, Translated har fremlagt om fremskridtene inden for MT-kvalitet, muligvis det mest overbevisende bevis på succes i stor skala set i både MT- og AI-samfundene generelt. Faktisk mener mange AI-forskere, at løsningen af sprogoversættelsesproblemet svarer til at producere kunstig generel intelligens (AGI). Translateds opdagelse har således for første gang i historien kvantificeret den hastighed, hvormed vi nærmer os singulariteten i kunstig intelligens, det hypotetiske fremtidige tidspunkt, hvor kunstig intelligens transcenderer menneskelig intelligens.