The article has been translated automatically. Any images and tables cited in the articles can be found by downloading the magazine issue in PDF format. Show original:
The article has been translated automatically. Any images and tables cited in the articles can be found by downloading the magazine issue in PDF format. Show original:
Einführung: Die Verfügbarkeit universeller Kommunikationsinstrumente und ihre Auswirkungen auf das Gesundheitswesen
Jedem zu erlauben, in seiner eigenen Sprache zu verstehen und verstanden zu werden, ist eine der bedeutendsten Herausforderungen für die Menschheit. Dies zu erreichen, wird eine beispiellose Zusammenarbeit zwischen den Menschen erleichtern. Stellen Sie sich zum Beispiel vor, dass wissenschaftliche Forschung in der Sprache jedes Forschers verfügbar wäre, sobald sie veröffentlicht wurde. Davon sind wir nicht weit entfernt, wie die Forschung zeigt, die wir bei Translated, einem globalen Sprachdienstleister und Pionier von KI-gestützten Übersetzungsdiensten, durchführen. Diese bahnbrechende Forschung wurde auf der letzten Jahrestagung der Association for Machine Translation in the Americas (AMTA) in Orlando vorgestellt.
Durch die Analyse der Bearbeitungen von 136.000 der besten professionellen Übersetzer der Welt auf 2 Milliarden Sätze, die von automatischer Übersetzungssoftware (maschinelle Übersetzung) verarbeitet wurden, konnten wir zum ersten Mal in der Geschichte die Geschwindigkeit quantifizieren, mit der wir uns der Singularität in der Übersetzung nähern. Die Einzigartigkeit wird erreicht, wenn die leistungsfähigsten professionellen Übersetzer die gleiche Zeit damit verbringen, eine durch maschinelle Übersetzung (MT) erstellte Übersetzung zu korrigieren, wie sie eine von ihren Kollegen erstellte korrigieren.
Im medizinischen Bereich ist das Durchbrechen von Sprachbarrieren noch wirkungsvoller als in anderen Bereichen. Diese Barrieren verhindern, dass Patienten ihre klinischen Zustände klar verstehen und erschweren es ihnen, die notwendige Therapie korrekt einzuhalten. Darüber hinaus erschweren diese Barrieren es Ärzten, wenn nicht gar unmöglich, die erforderliche Einwilligung zur Pflege zu erhalten und die für Diagnosen und Forschung erforderlichen Daten und Informationen zu begrenzen. Heute bieten viele größere Gesundheitseinrichtungen Dolmetscherdienste an, die jedoch mit erheblichen Kosten verbunden sind. Daher verlassen sich die meisten Organisationen im medizinischen Sektor immer noch auf kulturelle Mediatoren oder DIY-Lösungen wie Smartphone-Apps. Die COVID-19-Pandemie hat die Notwendigkeit, dieses Problem anzugehen, wichtiger denn je gemacht. Nach Angaben der EuropäischenKommission1erhöhte die Pandemie die Nachfrage nach Übersetzungen in der Gesundheitsbranche um 49 %. Glücklicherweise drängt der technologische Fortschritt die Gesundheitsgemeinschaft, maschinelle Übersetzung als Mittel zur Überwindung von Sprachbarrieren zu betrachten, und universelle Kommunikationsinstrumente sind nah genug, um ad equate Unterstützung zu bieten.
Wir gehen davon aus, dass die maschinelle Übersetzung einen radikal positiven Einfluss auf die Gesundheitsbranche haben wird. Mögliche Anwendungen sind in drei Hauptbereichen:
– Die Übersetzung von Informationen für die allgemeine
– Die Übersetzung von Fachpublikationen wie wissenschaftlichen Arbeiten, Patenten und Krankheitsberichten. Dies ermöglicht den Zugang zu globalen Forschungsstudien und realen Daten (z. B. klinische Studien und Arzneimittelforschung).
– Nahtlose Arzt-Patientenkommunikation und die Sammlung von Patienten-Feedback-Sammlung, auch aus Diskussionen in den sozialen Medien unter Hier können wir MT mit automatischer Spracherkennung (ASR) und Text-to-Speech (TTS) -Technologien kombinieren, um gesprochene Sprache zu unterstützen.
Allerdings wird maschinelle Übersetzung im Gesundheitswesen nur dann gute Leistungen erbringen, wenn sie Übersetzungen liefert, die so gut sind wie die von Übersetzungsexperten. Bei Translated überwachen wir seit 2011 die MT-Qualität und haben kürzlich beschlossen, die riesige Menge an Daten, die wir gesammelt haben, zu verwenden, um zu messen, wie weit wir von der Bereitstellung von maschinellen Übersetzungen in menschlicher Qualität entfernt sind. Wenn wir die Singularität in der Übersetzung erreichen, können wir die automatische Echtzeit-Übersetzung in fast jedem de Vice zu einem sehr zugänglichen Preis integrieren.
Eine kurze Geschichte der maschinellen Übersetzung
Das Konzept der automatischen Übersetzung wurde zum ersten Mal im 9.Jahrhundert erwähnt, als ein arabischer Kryptograf Techniken für die systematische Sprachübersetzung einführte, die unglaublich relevantsind2. Die erste öffentliche Demonstration der maschinellen Übersetzung wurde 1954 in den Vereinigten Staaten3durchgeführt. Es war ein kleines Experiment, aber es ermutigte die Forscher, voranzukommen. Frühe Systeme stützten sich auf zweisprachige Wörterbücher und Regeln, die festlegen, wie Wörter oder Sätze aus einer Ausgangssprache in eine Zielsprache zu übersetzen sind. Als nächstes wurde ein statistischer Ansatz entwickelt: Durch die Analyse großer Mengen menschlicher Übersetzungen begannen Maschinen, die Äquivalenz einer Phrase in der Zielsprache vorherzusagen. Der Ansatz des phrasenorientierten Musterlernens und der Musterprognose trieb die erste Version von Google Translate in den frühen 2000er Jahren voran.
Heute verlassen sich Google Translate und die fortschrittlichsten maschinellen Übersetzungsmaschinen auf auf Deep Learning basierende neuronale Netzwerkmodelle, um die endgültigen Ergebnisse zu lernen und vorherzusagen. Dies ist eine tiefere, zuverlässigere Form der Mustererkennung und -vorhersage. Bei dieser Art von System wird die Übersetzung durch ein einzelnes Sequenzmodell erzeugt, das trainiert wird, ein Wort nach dem anderen vorherzusagen, wobei der gesamte Ausgangssatz und die bereits bereitgestellte Übersetzung berücksichtigt werden.
Im Jahr 2017 führte ein Konsortium aus Translated, der Fondazione Bruno Kessler, der University of Edinburgh und TAUS die erste adaptive maschinelle Übersetzung ModernMT4ein. Ursprünglich war es ein von der Europäischen Union unterstütztes Forschungsprojekt5 , das später zu Open-Source-Software und einem kommerziellen Service von Translated wurde. In diesem neuen Modell lernt MT in Echtzeit aus dem korrigierenden Feedback des Übersetzers, ohne das Übersetzungsmodell neu zu trainieren. Die Idee für adaptive maschinelle Übersetzung geht auf ein vorheriges Forschungsprojekt von Translated, der Fondazione Bruno Kessler, der University of Edinburgh und der Le Mans University zurück, das erneut von der Europäischen Union gesponsert6wurde. Die erste Idee war es, ein Werkzeug zu erstellen, um maschinelle Übersetzungsergebnisse zu bearbeiten und Lokalisierungsworkflows zu verwalten. Das Forschungsziel war ein MT-System, das aus den Korrekturen der Übersetzer lernen und sich im Laufe der Zeit automatisch verbessern konnte. Die MT-Komponente der Lösung wurde später getrennt, um sich auf das Bearbeitungstool zu konzentrieren, das schließlich 2014 als Open-Source-Software veröffentlicht wurde. Die Europäische Kommission hat das Projekt zu den Projekten mit dem höchsten Innovationspotenzial gezählt, die durch das Siebte Rahmenprogramm finanziert werden. Translated verfeinerte den Forschungs-Prototypen weiter und entwickelte eine kommerzielle Version7, Matecat, ein kostenloses computergestütztes Übersetzungstool und eine MT-Bearbeitungssoftware, die das Unternehmen als exklusives Produktionswerkzeug annahm. Mit Matecat und ModernMT drängt Translated hart auf eine perfekte Symbiose zwischen menschlicher Kreativität und maschineller Intelligenz: Durch die Beseitigung überflüssiger Aufgaben ermöglicht KI Profis, sich auf die Nuancen der Sprache zu konzentrieren und die Qualität der Übersetzung zu verbessern. Diese Synergie gibt Linguisten bessere Vorschläge, während MT weiter lernt. Gemeinsam werden sie jeden Tag effizienter, anpassungsfähiger und kostengünstiger.
Über den Prozess und die gesammelten Daten
Im Jahr 2011 standardisierte Translated eine höchst zuverlässige Metrik, um die MT-Qualität genau zu bewerten. Wir nennen es Time to Edit (tte): Dies ist die durchschnittliche Zeit pro Wort, die von den leistungsfähigsten professionellen Übersetzern benötigt wird, um MT vorgeschlagene Übersetzungen zu überprüfen und zu korrigieren. Dies ermöglicht es, von automatisierten Schätzungen, die noch in der Industrie verwendet werden, zu Messungen des menschlichen kognitiven Aufwands zu wechseln und die Qualitätsbewertung den traditionell für die Aufgabe verantwortlichen Personen zuzuweisen: professionellen Übersetzern. Wir verfolgen Time to Edit seit fast einem Jahrzehnt und sammeln über 2 Milliarden Bearbeitungen von Sätzen, die effektiv von 136.000 professionellen Übersetzern weltweit über mehrere Fachbereiche hinweg übersetzt wurden, von der Literatur bis zur technischen Übersetzung, einschließlich Bereichen, in denen MT immer noch Probleme hat, wie z. B. Sprachtranskription. Die Linguisten wurden für die spezifischen Aufgaben ausgewählt, die sie mit der proprietären KI namensTRank8abgeschlossen haben, die Arbeitsleistungs- und Qualifikationsdaten von über 300.000 Freiberuflern sammelt, die in den letzten zwei Jahrzehnten mit dem Unternehmen gearbeitet haben. Die KI berücksichtigt über 30 Faktoren, einschließlich Lebenslauf-Match, Qualitätsleistung, Termintreue, Verfügbarkeit und Fachwissen in domänenspezifischen Themenbereichen.
In Matecat prüfen und korrigieren die Übersetzer die Übersetzungsvorschläge der MT-Engine ihrer Wahl. Die Daten wurden zunächst mit dem statistischen MT von Google (2015-2016), dann mit dem neuronalen MT von Google und zuletzt mit dem adaptiven neuronalen MT von Modern MT gesammelt, das 2018 eingeführt wurde und schnell zur bevorzugten Wahl unter fast allen unseren Übersetzern wurde. Translated sammelt seit über sieben Jahren die durchschnittliche Zeit, um ein Wort kontinuierlich zu bearbeiten.
Um die Probe zu verfeinern, haben wir nur Folgendes berücksichtigt:
– Abgeschlossene Aufträge mit einem hohen Qualitätsniveau.
– Sätze mit MT-Vorschlägen, die nicht mit zuvor übersetzten Textsegmenten aus Datenbanken übereinstimmen.
– Jobs, bei denen der Zielsprache eine große Menge an Daten zur Verfügung steht, zusammen mit nachgewiesener MT-Effizienz (Englisch, Französisch, Deutsch, Spanisch, Italienisch und Portugiesisch).
Aus dem resultierenden Pool von Sätzen haben wir Folgendes entfernt:
– Sätze, die keine Bearbeitungen erhielten, da sie keine Informationen über tte enthielten, und Sätze, deren Bearbeitung mehr als 10 Sekunden pro Wort dauerte, da sie auf Unterbrechungen und/oder ungewöhnlich hohe Komplexität hindeuten. Diese Verfeinerung war erforderlich, um den TTE-Vergleich über mehrere
– Arbeiten zur Anpassung an das Gebietsschema, d. h. Übersetzungen zwischen Varianten einer einzigen Sprache (z. B. britisches Englisch in amerikanisches Englisch), da diese für das Problem nicht repräsentativ sind bei
– Große Kundenaufträge, da sie hochgradig maßgeschneiderte Sprachmodelle und Translation Memories verwenden, in denen die TTE-Leistung weit über dem Durchschnitt liegt.
Die Bearbeitungszeit wird von zwei anderen Hauptvariablen als der MT-Qualität beeinflusst: der Entwicklung des Bearbeitungstools und der vom Übersetzer gelieferten Qualität. Der Einfluss dieser beiden Faktoren kann als vernachlässigbar angesehen werden, wenn man den von uns beobachteten langfristigen Verbesserungstrend betrachtet.
Ein überraschender linearer Trend, der sich der Singularität in der Übersetzung nähert
Grafisch dargestellt zeigen die TTE-Daten einen überraschend linearen Trend. Unsere anfängliche Hypothese, dies zu erklären, lautet, dass jede Einheit des Fortschritts auf den Stationen, die die Qualitätslücke schließt, exponentiell mehr Ressourcen erfordert als die vorherige Einheit, und wir setzen dementsprechend diese Ressourcen ein: Rechenleistung (Verdoppelung alle zwei Jahre), Datenverfügbarkeit (die Anzahl der Wörter, die in Falten bei einer durchschnittlichen jährlichen Wachstumsrate von 6,2% nach Nimdzi Insights übersetzt werden) und die Effizienz von Algorithmen für maschinelles Lernen (Berechnung für die Schulung erforderlich, 44-fache Verbesserung von 2012-2019, nach OpenAI9.
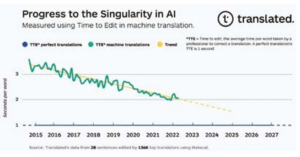
Abb. 1.
Fazit: Wie nah wir daran sind, Sprachbarrieren zu überwinden
Wenn sich die Fortschritte in der Qualität maschineller Übersetzungen mit dem aktuellen Trend fortsetzen, werden die leistungsfähigsten professionellen Übersetzer in etwa sechs Jahren die gleiche Zeit damit verbringen, eine durch maschinelle Übersetzung erstellte Übersetzung zu korrigieren, wie sie eine von ihren Kollegen erstellte korrigieren. Das genaue Datum, an dem wir die Singularität in der Übersetzung erreichen, könnte etwas variieren, aber der Trend ist klar. Wir sind daher kurz davor, in Echtzeit universelle, zugängliche Übersetzungstools bereitstellen zu können, die die Sprachbarrieren durchbrechen und es uns ermöglichen, die Gesundheitsergebnisse unserer Kunden zu verbessern und das Todesrisiko zu senken.
Aus Sicht der Forschung ist die Evidenz, die Translated über die Fortschritte bei der MT-Qualität geliefert hat, wahrscheinlich die überzeugendste Evidenz für den Erfolg im großen Maßstab, die sowohl in der MT- als auch in der KI-Gemeinschaft im Allgemeinen zu sehen ist. Tatsächlich glauben viele KI-Forscher, dass die Lösung des Sprachübersetzungsproblems der Herstellung künstlicher allgemeiner Intelligenz (AGI) gleichkommt. Die Entdeckung von Translated hat somit zum ersten Mal in der Geschichte die Geschwindigkeit quantifiziert, mit der wir uns der Singularität in der künstlichen Intelligenz nähern, dem hypothetischen zukünftigen Zeitpunkt, an dem künstliche Intelligenz die menschliche Intelligenz übersteigt.