The article has been translated automatically. Show original:
The article has been translated automatically. Show original:
Introdução: A disponibilidade de ferramentas universais de comunicação e seu impacto nos cuidados de saúde
Permitir que todos compreendam e sejam compreendidos em sua própria língua é um dos desafios mais significativos para a humanidade. Conseguir isso facilitará uma colaboração sem precedentes entre os seres humanos. Imagine, por exemplo, se a pesquisa científica estivesse disponível na língua de todos os pesquisadores assim que fosse publicada. Não estamos longe disso, como comprovado pela pesquisa que realizamos na Translated, um provedor global de serviços linguísticos e pioneiro de serviços de tradução com tecnologia AI. Esta pesquisa inovadora foi apresentada na última conferência anual da Association for Machine Translation in the Americas (AMTA) em Orlando.
Ao analisar as edições feitas por 136.000 dos melhores tradutores profissionais do mundo para 2 bilhões de frases processadas por software de tradução automática (tradução automática), pela primeira vez na história, conseguimos quantificar a velocidade com que estamos nos aproximando da singularidade na tradução. A singularidade é alcançada quando os tradutores profissionais com melhor desempenho gastam o mesmo tempo corrigindo uma tradução produzida por tradução automática (MT) como fazem corrigindo uma concluída por seus pares.
No campo médico, quebrar barreiras linguísticas é ainda mais impactante do que em outras áreas. Essas barreiras impedem que os pacientes compreendam claramente suas condições clínicas, dificultando assim a adesão correta à terapia necessária. Além disso, essas barreiras dificultam, se não impossibilitam, que os médicos obtenham o consentimento necessário para cuidar e limitar os dados e informações necessários para diagnósticos e pesquisas. Hoje, muitas instituições de saúde maiores oferecem serviços de intérprete, mas estes têm custos significativos. Assim, a maioria das organizações do setor médico ainda conta com mediadores culturais ou soluções DIY, como aplicativos para smartphones. A pandemia de Covid19 tornou a necessidade de abordar este problema mais importante do que nunca. De acordo com a Comissão1Europeia, a pandemia aumentou a demanda por tradução em 49% no setor de saúde. Felizmente, os avanços tecnológicos estão empurrando a comunidade de saúde a olhar para a tradução automática como um meio de superar as barreiras linguísticas, e as ferramentas de comunicação universais estão perto o suficiente para fornecer suporte.
Esperamos que a tradução automática tenha um impacto positivo radical no setor de saúde. As aplicações potenciais estão em três áreas principais:
– A tradução de informações para o público em geral
– A tradução de publicações especializadas, como artigos científicos, patentes e relatórios de doenças. Isso fornecerá acesso a estudos de pesquisa globais e dados do mundo real (por exemplo, ensaios clínicos e descoberta de medicamentos).
– Comunicação perfeita do paciente com o médico e a coleta de feedback do paciente, mesmo a partir de discussões que acontecem nas mídias sociais entre Aqui, podemos combinar MT com tecnologias de reconhecimento automático de fala (ASR) e texto para fala (TTS) para apoiar a linguagem falada.
No entanto, a tradução automática terá um bom desempenho nos cuidados de saúde apenas quando fornecer traduções tão boas quanto as feitas por profissionais de tradução. Na Translated, monitoramos a qualidade da MT desde 2011 e, recentemente, decidimos usar a enorme quantidade de dados que coletamos para medir o quão longe estamos de fornecer tradução automática de qualidade humana. Quando alcançamos a singularidade na tradução, podemos integrar a tradução automática em tempo real em quase todos os vícios a um custo muito acessível.
Uma Breve História da Tradução Automática
O conceito de tradução automática foi mencionado pela primeira vez no 9 IX século, quando um criptógrafo árabe introduziu técnicas de tradução sistemática de idiomas que são, incrivelmente, ainda2relevantes. No entanto, a primeira demonstração pública de tradução automática foi feita em 1954 nos Estados3Unidos. Foi um experimento pequeno, mas encorajou os pesquisadores a avançar. Os primeiros sistemas baseavam-se em dicionários bilíngues e regras que indicavam como traduzir palavras ou frases de um idioma de origem para um idioma de destino. Em seguida, foi desenvolvida uma abordagem estatística: ao analisar grandes volumes de traduções humanas, as máquinas começaram a prever a equivalência de uma frase no idioma de destino. A abordagem focada em aprendizado de padrões e previsão de padrões levou a primeira versão do Google Tradutor no início dos anos 2000.
Hoje, o Google Tradutor e os mecanismos de tradução automática mais avançados contam com modelos de redes neurais baseados em aprendizado profundo para aprender e prever os resultados finais. Esta é uma forma mais profunda e confiável de detecção e previsão de padrões. Nesse tipo de sistema, a tradução é produzida por um único modelo de sequência treinado para prever uma palavra de cada vez, considerando toda a frase de origem e a tradução que já foi fornecida.
Em 2017, um consórcio formado pela Translated, a Fondazione Bruno Kessler, a Universidade de Edimburgo e a Taus introduziu a primeira tradução automática adaptativa, a ModernMT4. Foi inicialmente um projeto de pesquisa apoiado pela União Europeia que mais5 tarde se tornou um software de código aberto e um serviço comercial desenvolvido pela Translated. Neste novo modelo, a MT aprende em tempo real a partir do feedback corretivo do tradutor sem treinar novamente o modelo de tradução. A ideia da tradução automática adaptativa remonta a um projeto de pesquisa anterior conduzido pela Translated, pela Fondazione Bruno Kessler, pela Universidade de Edimburgo e pela Universidade de Le Mans, patrocinado novamente pela União Europeia6. A ideia inicial era criar uma ferramenta para editar os resultados da tradução automática e gerenciar os fluxos de trabalho de localização. O objetivo da pesquisa era um sistema de MT que pudesse aprender com as correções dos tradutores e melhorar automaticamente ao longo do tempo. O componente MT da solução foi posteriormente separado para se concentrar na ferramenta de edição, que foi finalmente lançada como software de código aberto em 2014. A Comissão Europeia incluiu o projeto entre aqueles com maior potencial de inovação financiados pelo Sétimo Programa-Quadro. A Translated refinou ainda mais o protótipo de pesquisa e criou uma versão comercial,7o Matecat, uma ferramenta gratuita de tradução assistida por computador e software de edição MT que a empresa adotou como sua ferramenta de produção exclusiva. Com o Matecat e o ModernMT, a Translated está empenhada em criar uma simbiose perfeita entre a criatividade humana e a inteligência da máquina: ao remover tarefas redundantes, a IA permite que os profissionais se concentrem nas nuances da linguagem, melhorando a qualidade da tradução. Essa sinergia dá aos linguistas melhores sugestões enquanto a MT continua aprendendo. Juntos, eles se tornam mais eficientes, adaptáveis e econômicos todos os dias.
Sobre o Processo e os Dados Recolhidos
Em 2011, a Translated padronizou e estabeleceu uma métrica altamente confiável para avaliar a qualidade da MT com precisão. Chamamos isso de Time to Edit (TTE): este é o tempo médio por palavra exigido pelos tradutores profissionais com melhor desempenho para verificar e corrigir as traduções sugeridas pela MT. Isso possibilita a mudança de estimativas automatizadas ainda em uso na indústria para medições do esforço cognitivo humano, reatribuindo a avaliação da qualidade às pessoas tradicionalmente responsáveis pela tarefa: tradutores profissionais. Acompanhamos o Time to Edit há quase uma década, coletando mais de 2 bilhões de edições em frases efetivamente traduzidas por 136.000 tradutores profissionais em todo o mundo que trabalham em vários domínios de assunto, desde literatura até tradução técnica e incluindo campos em que a MT ainda está com dificuldades, como transcrição de fala. Os linguistas foram selecionados para os trabalhos específicos que concluíram usando a IA proprietária chamada TRank8, que reúne dados de desempenho e qualificação de trabalho de mais de 300.000 freelancers que trabalharam com a empresa nas últimas duas décadas. A IA considera mais de 30 fatores, incluindo correspondência de currículo, desempenho de qualidade, registro de entrega no prazo, disponibilidade e experiência em áreas temáticas específicas do domínio.
Trabalhando no Matecat, os tradutores verificam e corrigem as sugestões de tradução fornecidas pelo mecanismo MT de sua escolha. Os dados foram inicialmente coletados usando o MT estatístico do Google (2015-2016), depois o MT neural do Google e, mais recentemente, o MT neural adaptativo do Modern MT, introduzido em 2018, que rapidamente se tornou a escolha preferida entre quase todos os nossos tradutores. A Translated vem coletando o tempo médio para editar uma palavra continuamente há mais de sete anos.
Para refinar a amostra, consideramos apenas o seguinte:
– Trabalhos concluídos entregues com um alto nível de qualidade.
– Frases com sugestões de MT que não tiveram correspondência de bancos de dados de segmentos de texto previamente traduzidos.
– Trabalhos em que o idioma de destino tem uma grande quantidade de dados disponíveis, juntamente com eficiência comprovada de MT (inglês, francês, alemão, espanhol, italiano e português).
Do conjunto de frases resultante, removemos:
– Frases que não receberam nenhuma edição, pois não forneceram informações sobre TTE, e frases que levaram mais de 10 segundos por palavra para serem editadas, pois sugerem interrupções e/ou complexidade incomumente alta. Este refinamento foi necessário para possibilitar a comparação de TTE em vários
– Trabalhar na adaptação à localidade, ou seja, traduções entre variantes de um único idioma (por exemplo, inglês britânico para inglês americano), uma vez que estas não são representativas do problema em
– Grandes empregos de clientes, uma vez que empregam modelos de linguagem altamente personalizados e memórias de tradução nas quais o desempenho do TTE é muito melhor do que a média.
O Time to Edit é impactado por duas variáveis principais além da qualidade MT: a evolução da ferramenta de edição e a qualidade entregue pelo tradutor. A influência desses dois fatores pode ser considerada desprezível quando considerada a tendência de melhora de longrun que observamos.
Uma Surpreendente Tendência Linear Aproximando-se da Singularidade na Tradução
Quando plotados graficamente, os dados TTE mostram uma tendência surpreendentemente linear. Nossa hipótese inicial para explicar isso é que cada unidade de progresso para alas que fecham a lacuna de qualidade requer exponencialmente mais recursos do que a unidade anterior e, consequentemente, implantamos esses recursos: poder de computação (dobrando a cada dois anos), disponibilidade de dados (o número de palavras traduzidas em vincos a uma taxa de crescimento anual composta de 6,2% de acordo com Nimdzi Insights) e a eficiência dos algoritmos de aprendizado de máquina (computação necessária para treinamento, 44x melhoria de 2012-2019, de acordo com OpenAI 9
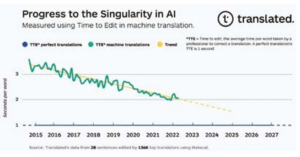
Fig. 1.
Conclusão: Quão perto estamos de quebrar as barreiras linguísticas
Se o progresso na qualidade da tradução automática continuar com a tendência atual, em cerca de seis anos, os tradutores profissionais com melhor desempenho passarão o mesmo tempo corrigindo uma tradução produzida pela tradução automática, assim como corrigindo uma concluída por seus pares. A data exata em que chegaremos à singularidade na tradução pode variar um pouco, mas a tendência é clara. Estamos, portanto, perto de poder fornecer ferramentas de tradução em tempo real, universais e acessíveis que quebrarão as barreiras linguísticas, permitindo melhorar os resultados de saúde dos clientes, diminuindo o risco de morte.
Do ponto de vista da pesquisa, a evidência que a Translated forneceu sobre o progresso na qualidade da MT é possivelmente a evidência mais convincente de sucesso em escala vista nas comunidades de MT e AI em geral. De fato, muitos pesquisadores de IA pensam que resolver o problema da tradução de idiomas é equivalente a produzir inteligência geral artificial (agi). A descoberta da Translated quantificou, pela primeira vez na história, a velocidade com que estamos nos aproximando da singularidade da inteligência artificial – o hipotético ponto futuro no tempo em que a inteligência artificial transcende a inteligência humana.